DVC 3 Years 🎉 and 1.0 Pre-release 🚀
Today, we've got three big announcements.
🎉 3rd-year anniversary of DVC
🚀 DVC 1.0 pre-release is ready
⭐ DVC has reached 5K GitHub starts (coincidentally on the same day)
We'll share what we've learned from our journey, how users helped for the new release and how DVC is growing.



DVC 3rd-year anniversary
3 years anniversary!
Three years ago on May 4th, 2017, I published the first blog post about DVC. The first DVC discussion on Reddit. Until that point, DVC was a private project between myself and Ruslan. Today, things look very different.
Today, DVC gets recognized at professional conferences: people spot our logo, and sometimes even our faces, and want to chat. There's much more content about DVC coming from bloggers than from inside our organization. We're seeing more and more job postings that list DVC as a requirement, and we're showing up in data science textbooks. When we find a new place DVC is mentioned, we celebrate in our Slack - we've come a long way!
The data science and ML space is fast-paced and vibrant, and we're proud that DVC is making an impact on discussions about best practices for healthy, sustainable ML. Every week, we chat with companies and research groups using DVC to make their teams more productive. We're proud to be part of the growing MLOps movement: so far, a majority of CI/CD for ML projects are implemented with DVC under the hood.
I can confidently say that DVC wouldn't have been possible without a lot of help from our community. Thank you to everyone who has supported us:
DVC core team. The DVC team has been the force driving our project's evolution - we've grown from 2 to 12 full-time engineers, developers, and data scientists. Half of the team is purely focus on DVC while the other half on related to DVC new projects. We often get feedback about how fast our team answers user questions - we've been told our user support is one of DVC's "killer features". It's all thanks to this amazing team.
DVC contributors. As of today, the DVC code base has 126 individual contributors. Many of these folks put hours into their code contribution. We're grateful for their tenacity and generosity.

Documentation contributors. Another 124 people contributed to the DVC documentation and the website. Every time a new person tries out DVC, they benefit from the hard work that's gone into our docs.
Active community members. Active DVC users help our team understand and better anticipate their needs and identify priorities for development. They share bright ideas for new features, locate and investigate bugs in code, and welcome and support new users.
People who give DVC a shot. Today, there are thousands of data scientists, ML engineers, and developers using DVC on a regular basis. The number of users is growing every week. Our Discord channel has almost two thousand users. Hundreds more connect with us through email and Twitter. To everyone willing to try out DVC, thank you for the opportunity.
DVC 1.0 is the result of 3 years of learning
All these contributions, big and small, have a collective impact on DVC's development. I'm happy (and a bit nervous) to announce that a pre-release of a brand new DVC 1.0 is ready for public beta testing.
You can install the 1.0 pre-release from the master branch in our repo (instruction here) or through pip:
$ pip install --upgrade --pre dvcThe new DVC is inspired by discussions and contributions from our community - both fresh ideas and bug reports 😅.
Here are the most significant features we’re excited to be rolling out soon:
Run cache
Learnings: Forcing users to make Git commits for each ML experiment creates too much overhead.
DVC 1.0 has a "long memory" of DVC commands runs. This means it can identify if
a dvc repro has already been run and save compute time by returning the cached
result - even if you didn't Git commit that past run.
We added the run-cache with CI/CD systems and other MLOps and DataOps automation
tools in mind. No more auto-commits needed after dvc repro in the CI/CD system
side.
Multi-stage DVC files
Learnings: ML pipelines evolve much faster than data engineering pipelines.
We redesigned the way DVC records data processing stages with metafiles, to make pipelines more interpretable and editable. All pipeline stages are now saved in a single metafile, with all stages stored together instead of in separate files.
Data hash values are no longer stored in the pipeline metafile. This improves human-readability.
stages:
process:
cmd: ./process_raw_data raw_data.log users.csv
deps:
- raw_data.log
params:
- process_file
- click_threshold
outs:
- users.csv
train:
cmd: python train.py
deps:
- users.csv
params:
- epochs
- log_file
- dropout
metrics_no_cache:
- summary.json
metrics:
- logs.csv
outs:
- model.pklPlots
Learnings: Versioning metrics and plots are no less important than data versioning.
Countless users asked us when we'd support metrics visualizations. Now it's
here: DVC 1.0 introduces metrics file visualization commands, dvc metrics diff
and dvc plots show. DVC plots are powered by the
Vega-Lite graphic library.
This function is designed not only for showing visualizations based on the current state of your project, but it can also combine multiple plots from your Git history in a single chart so you can compare results across commits. Users can visualize how, for example, their model accuracy in the latest commit differs from another commit (or even multiple commits).
$ dvc plots diff -d logs.csv HEAD HEAD^ d1e4d848 baseline_march
file:///Users/dmitry/src/plot/logs.csv.html
$ open logs.csv.html
$ dvc plots diff -d logs.csv HEAD HEAD^ d1e4d848 baseline_march \
-x loss --template scatter
file:///Users/dmitry/src/plot/logs.csv.html
$ open logs.csv.html
Data transfer optimizations
Learnings: In ML projects, data transfer optimization is still the king.
We've done substantial work on optimizing data management commands, such as
dvc pull / push / status -c / gc -c. Now, based on the amount of data, DVC can
choose an optimal data remote traversing strategy.
Mini-indexes were introduced to help DVC instantly check data directories instead of iterating over millions of files. This also speeds up file adding/removing to large directories.
More optimizations are included in the release based on performance bottlenecks we profiled. More detailed benchmark report that shows how many second it takes to run a specific commands on 2M images directory.

Hyperparameter tracking
Learnings: ML pipeline steps depends only on a subset of config file.
This feature was actually released in the last DVC 0.93 version (see params docs. However, it is an important step to support configuration files and ML experiments in a more holistic way.
For more information on the new features…
Each of the big new features and improvements deserve a separate blog post. We will be posting more - please stay in touch.
I hope our the most active users will find time to check the DVC pre-release version and provide their feedback. The installation instruction is on our website.
5000 GitHub stars
Activity on our GitHub page has grown organically since the DVC repo went public on May 4th, 2017. Coincidentally, today, in the 3rd year anniversary we have reached 5000 starts:
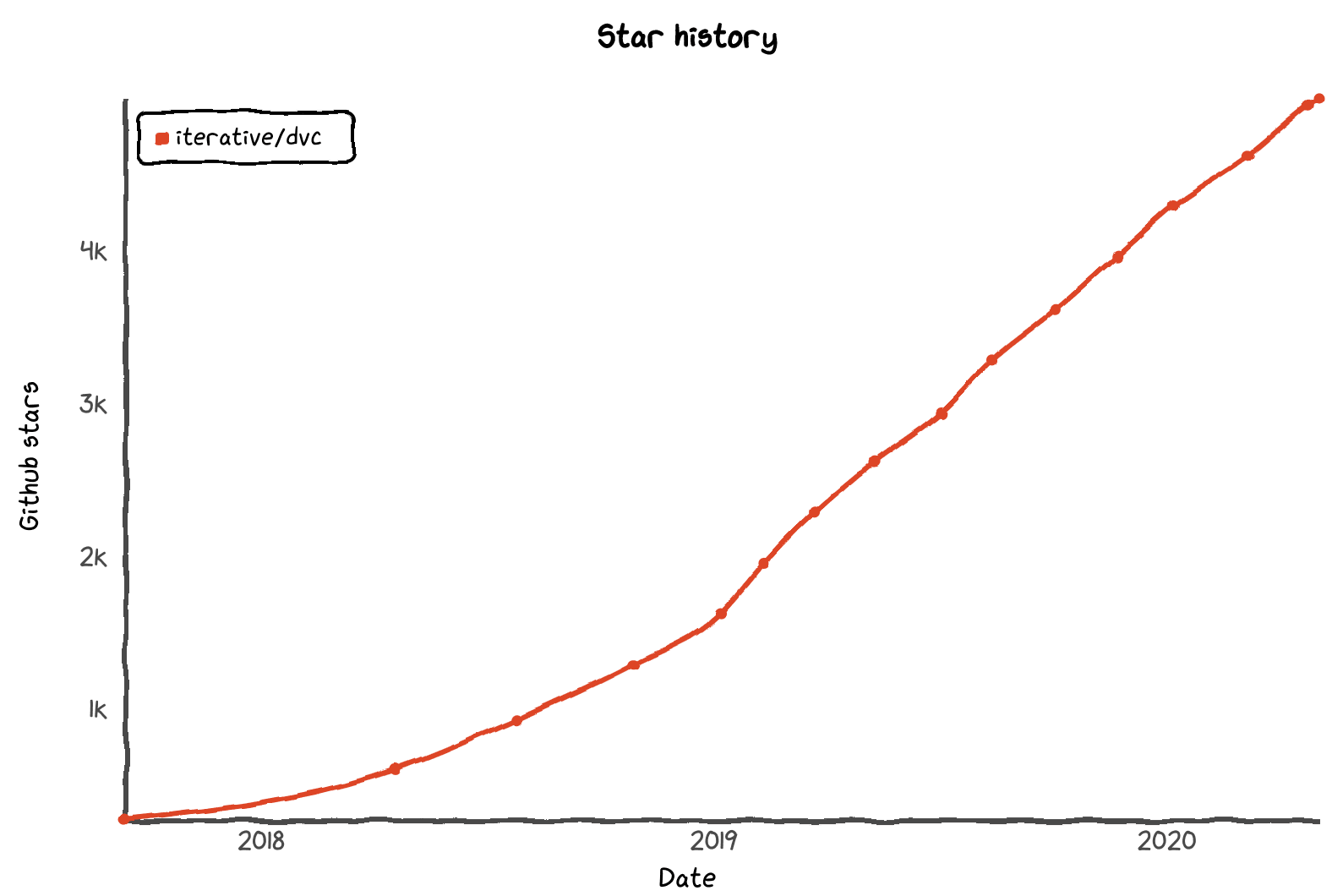
Thank you!
Thank you again to all DVC contributors, community members, and users. Every piece of your help is highly appreciated and will bring huge benefits to the entire ecosystem of data and ML projects.
Stay healthy and safe, wherever you are in the world. And be in touch on Twitter, and our Discord channel.