June ’19 DVC❤️Heartbeat
Every month we are sharing here our news, findings, interesting reads, community takeaways, and everything along the way. Some of those are related to our brainchild DVC and its journey. The others are a collection of exciting stories and ideas centered around ML best practices and workflow.





Thanks to the amazing Signaturit Tech team for this photo!
News and links
We want to start by saying to our users, contributors, and community members how grateful we are for the fantastic work you are doing contributing to DVC, giving talks about DVC, sharing your feedback, use cases and your concerns. A huge thank you to each of you from the DVC team!
We would love to give back and support any positive initiative around DVC — just let us know here and we will send you a bunch of cool swag, connect to a tech expert or find another way to support your project. Our DMs on Twitter are open, too.
And if you have 4 minutes to spare, we are conducting out first DVC user survey and would love to hear from you!
Aside from admiring great DVC-related content from our users we have one more reason to particularly enjoy the past month — DVC team went to Cleveland to attend PyCon 2019 and it was a blast!

We had it all. Running our first ever conference booth, leading an impromptu unconference discussion and arranging some cool #SupportOpenSource activities was great! Last-minute accommodation cancellations, booth equipment delivery issues, and being late for our very own talk was not so great. Will be sharing more about it in a separate blogpost soon.
Here is Dmitry Petrov’s PyCon talk and slides on Machine learning model and dataset versioning practices.
We absolutely loved being at PyCon and can’t wait for our next conference!
Our team is so happy every time we discover an article featuring DVC or addressing one of the burning ML issues we are trying to solve. Here are some of the links that caught our eye past month:
A brilliant comprehensive read on the current data management issues. It might be the best article we have ever read on this subject. Every word strongly resonates with our vision and ideas behind DVC. Highly recommended by DVC team!
The Rise of DataOps (from the ashes of Data Governance)

Legacy Data Governance is broken in the ML era. Let’s rebuild it as an engineering discipline. At the end of the transformation, data governance will look a lot more like DevOps, with data stewards, scientists, and engineers working closely together to codify the governance policies.
First Impressions of Data Science Version Control (DVC)
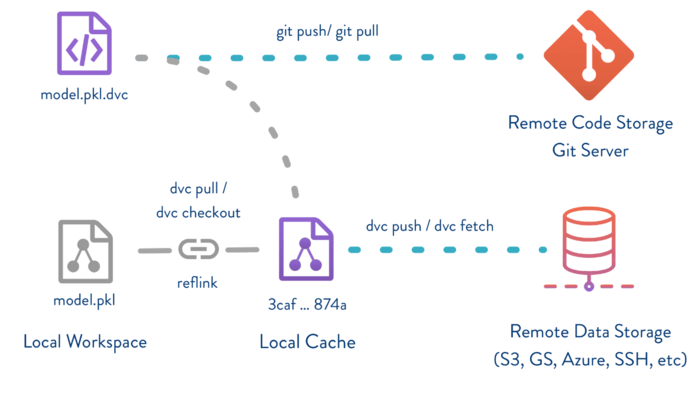
In 2019, we tend to find organizations using a mix of git, Makefiles, ad hoc scripts and reference files to try and achieve reproducibility. DVC enters this mix offering a cleaner solution, specifically targeting Data Science challenges.
- Versioning and Reproducibility with MLV-tools and DVC: Talk and Tutorial by Stéphanie Bracaloni and Sarah Diot-Girard.

Becoming a machine learning company means investing in foundational technologies

With an eye toward the growing importance of machine learning, we recently completed a data infrastructure survey that drew more than 3,200 respondents.
Discord gems
There are lots of hidden gems in our Discord community discussions. Sometimes they are scattered all over the channels and hard to track down.
We are sifting through the issues and discussions and share with you the most interesting takeaways.
Q: Does DVC support Azure Data Lake Gen1?
Azure data lake is HDFS compatible. And DVC supports HDFS remotes. Give it a try and let us know if you hit any problems here.
Q: An excellent discussion on versioning tabular (SQL) data. Do you know of any tools that deal better with SQL-specific versioning?
It’s a wide topic. The actual solution might depend on a specific scenario and what exactly needs to be versioned. DVC does not provide any special functionality on top of databases to version their content.
Depending on your use case, our recommendation would be to run SQL and pull the result file (CSV/TSV file?) that then can be used to do analysis. This file can be taken under DVC control. Alternatively, in certain cases source files (that are used to populate the databases) can be taken under control and we can keep versions of them, or track incoming updates.
Read the discussion to learn more.
Q: How does DVC do the versioning between binary files? Is there a binary diff, similar to git? Or is every version stored distinctly in full?
DVC is just saving every file as is, we don’t use binary diffs right now. There won’t be a full directory (if you added just a few files to a 10M files directory) duplication, though, since we treat every file inside as a separate entity.
Q: Is there a way to pass parameters from e.g. dvc repro to stages?
The simplest option is to create a config file — json or whatnot — that your scripts would read and your stages depend on.
Q: What is the best way to get cached output files from different branches simultaneously? For example, cached tensorboard files from different branches to compare experiments.
There is a way to do that through our (still not officially released) API pretty easily. Here is an example script how it could be done.
Q: Docker and DVC. To being able to push/pull data we need to run a git clone to get DVC-files and remote definitions — but we worry that would make the container quite heavy (since it contains our entire project history).
You can do git clone — depth 1, which will not download any history except the
latest commits.
Q: After DVC pushing the same file, it creates multiple copies of the same file. Is that how it’s supposed to work?
If you are pushing the same file, there are no copies pushed or saved in the cache. DVC is using checksums to identify files, so if you add the same file once again, it will detect that cache for it is already in the local cache and wont copy it again to cache. Same with dvc push, if it sees that you already have cache file with that checksum on your remote, it won’t upload it again.
Q: How do I uninstall DVC on Mac (installed via pkg installer)?
Something like this should work:
$ which dvc
/usr/local/bin/dvc -> /usr/local/lib/dvc/dvc
$ ls -la /usr/local/bin/dvc
/usr/local/bin/dvc -> /usr/local/lib/dvc/dvc
$ sudo rm -f /usr/local/bin/dvc
$ sudo rm -rf /usr/local/lib/dvc
$ sudo pkgutil --forget com.iterative.dvcQ: How do I pull from a public S3 bucket (that contains DVC remote)?
Just add public URL of the bucket as an HTTP endpoint. See here for an example. https://remote.dvc.org/get-started is made to redirect to the S3 bucket anyone can read from.
Q: I’m getting the same error over and over about locking: ERROR: failed to lock before running a command — cannot perform the cmd since DVC is busy and locked. Please retry the command later.
Most likely it happens due to an attempt to run DVC on NFS that has some configuration problems. There is a well known problem with DVC on NFS — sometimes it hangs on trying to lock a file. The usual workaround for this problem is to allocate DVC cache on NFS, but run the project (git clone, DVC metafiles, etc) on the local file system. Read this answer to see how it can be setup.
If you have any questions, concerns or ideas, let us know in the comments below or connect with DVC team here. Our DMs on Twitter are open, too.