




Welcome to the June Heartbeat, our monthly roundup of cool happenings, good reads and up-and-coming developments in the DVC community.
News
In the beginning of May, we pre-released DVC 1.0. Ever since, we've been putting the final touches on 1.0- wrapping up features, fixing bugs 🐛, and responding to feedback from intrepid users trying the pre-release. To recap, here are some of the big features coming:
-
Plots powered by Vega-Lite We're building functions for visualizing metrics in your project, as well as comparing metrics across commits. We chose Vega-Lite plots because they're high-level, compatible with ML projects written in any language, and beautiful by default.
-
Human readable and writeable pipelines. We're reworking pipelines so you can modify dependencies, outputs, metrics, plots, and entire stages easily: via manual edits to a
.yamlpipeline fines. This redesign will consolidate pipeline.dvcfiles into a single file (yay, simpler working directory). No worries for pipeline enthusiasts- DVC 1.0 is backwards compatible, so your existing projects won't be interrupted. -
Run cache. One of the most exciting features is the run-cache, a local record of pipeline versions that have previously been run and the outputs of those runs. It can seriously cut down on compute time if you find yourself repeating pipeline executions. For our CI/CD users, it also offers a way to save the output of your pipeline- like models or results- without auto-commits.
DVC 1.0 work has been our top priority this past month, and we are extremely close to the releae. Think 1-2 weeks!
Another neat announcement: DVC moved up on ThoughtWorks Technology Radar! To quote ThoughtWorks:
In 2018 we mentioned DVC in conjunction with the versioning data for reproducible analytics. Since then it has become a favorite tool for managing experiments in machine learning (ML) projects. Since it's based on Git, DVC is a familiar environment for software developers to bring their engineering practices to ML practice. Because it versions the code that processes data along with the data itself and tracks stages in a pipeline, it helps bring order to the modeling activities without interrupting the analysts’ flow.
And here we are on the radar, in the Trial zone:
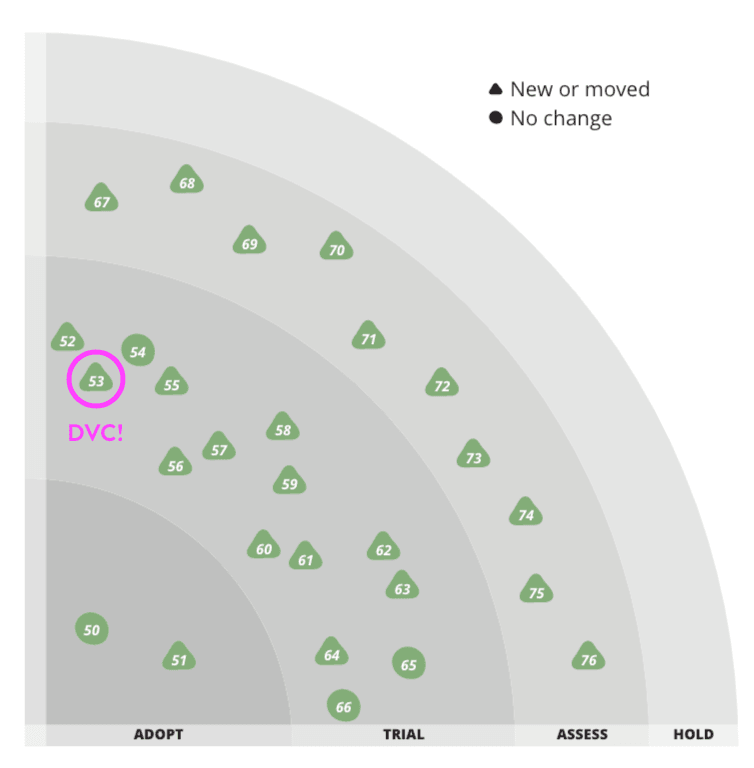
We are honored. In fact, this was validating in several ways. We field a lot of questions about our decision to build around Git, rather than creating a platform. It's awesome to know our approach is resonating with teams at the intersection of ML and software development. Thanks, ThoughtWorks!
Last up in company news: you might recall that in early May, we hosted an online meetup. Marcel Ribeiro-Dantas hosted guest talks from Elizabeth Hutton and Dean Pleban- we heard about constructing a new COVID-19 dataset, using DVC with transformer language models, and building custom cloud infrastructure for MLOps. There's also Q&A with the DVC team, where we fielded audience questions. A video of the meetup is available now, so check it out if you missed the event.
From the community
As usual, there's a ton of noteworthy action in the DVC community.
Derek Haynes, MLOps expert and new DVC Ambassador- wrote an excellent overview of using GitHub CodeSpaces. CodeSpaces is a new development environment (currently in beta) that we're eagerly watching. As Derek shows in his blog, it lets you have a Jupyter Notebook experience without sacrificing on development standards- he uses whisk to structure the project and manage Python package dependencies, and DVC to version the model training pipeline.
This use case is telling in the battle over Jupyter notebooks: we might just be able to have both a notebook and mature project management. Give Derek's blog a read and tell us what you think.
GitHub Codespaces for Machine Learning

DVC Ambassador Marcel gave a tutorial about DVC to a bioinformatics student group, and then an even bigger talk at the Federal University of Rio Grande de Norte. His talk focused on how to use DVC in the context of scientific reproducibility- specifically, large biological datasets, which are often transformed and processed several times before ML models are fit. In my experience, Git-flow is severely underutilized in life sciences research, so it's exciting to see Marcel's ideas getting a big audience.
Interessados(as) na área de Ciência de Dados? Na próxima sexta-feira as 14h teremos uma palestra sobre uma das novíssimas ferramentas da área, o DVC - Data Version Control!!! Não percam essa oportunidade. @ufrnbr @PropesqUFRN pic.twitter.com/AmXxz7ioVG
— ppgeecufrn (@ppgeecufrn) May 21, 2020
Also, Marcel is the first author of a new scientific paper about mobility data across 131 countries during the COVID-19 pandemic. The preprocessing pipeline is versioned with DVC. We don't know how Marcel gets this much done.
Dataset for country profile and mobility analysis in the assessment of COVID-19 pandemic
Also just released is a scientific paper by Christoph Jansen et al. about a framework for computational reproducibility in the life sciences that integrates DVC. The framework is called Curious Containers- definitely worth checking out for biomedical researchers interested in deep learning.
Curious Containers: A framework for computational reproducibility in life sciences with support for Deep Learning applications

In other work of vital interest to the good of humanity, this month has seen some awesome applictions of the public Reddit dataset we released in February. The dataset is designed for an NLP task of mighty importance: will Redditors vote that the poster is an asshole, or not?
Daniele Gentile beat our benchmark classifier (62% accuracy, but not bad for logistic regression!) with Doc2Vec embeddings and a 500-neuron network. He got 71% accuracy on held out data- nice! His blog is a fun read, and code's included if you want to follow along.
Artificial Intelligence confirms you are an a**hole
Elsewhere on the internet, data scientist Dan Cassin delivered this beautiful tweet:
Used a dataset from https://t.co/6yDX1A9Rga on @reddit's AITA, used NLTK for processing, TFIDF, then UMAP, and the result is the coolest, but most unhelpful graph I've ever made. @matplotlib pic.twitter.com/fYpuvwTIYE
— Dan Cassin (@Dan_Cassin) May 3, 2020
Last, I want to point you to two other excellent blogs. Venelin Valkov released a blog, Reproducible machine learning and experiment tracking pipeline with Python and DVC, that contains not only a detailed sample project but a livecoding video!
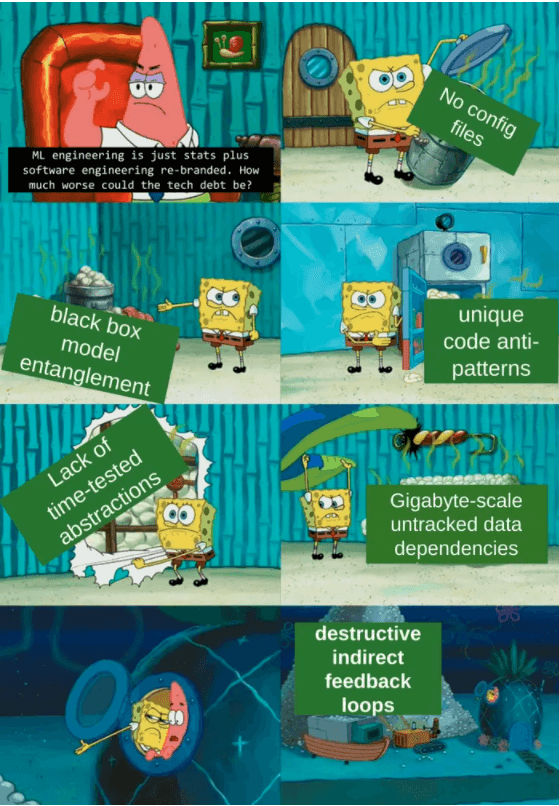
Matthew McAteer revisited the famous 2015 Hidden Technical Debt in Machine Learning Systems paper to ask which recommendations still work five years later. It's pretty great- please read it.
Coming up soon
There are a couple of events to look forward to in the next few weeks. I'll be speaking at two conferences: first, MLOps World about CI/CD and ML. Next, I'm organizing a workshop at the Virtual Conference on Computational Audiology. To get ready, I'm gathering resources about good computing practices for scientists and biomedical research labs- contributions are welcome.
Another talk on our radar is at EuroPython 2020. Engineer Hongjoo Lee will be talking about building a CI/CD workflow for ML with DVC- we're very interested to learn about their approach.
Lastly, ML REPA leader and new DVC Ambassador Mikhail Rozhkov is working on a Udemy course about DVC. Look for more updates this summer!
Thanks for reading this month. As always, we're proud of the ways our community works for better, more rigorous ML.