




What is the difference between using dvc exp run and dvc repro?
This is a really good question from @v2.03.99!
When you use dvc exp run, DVC automatically tracks each experiment run. Using
dvc repro leaves it to the user to track each experiment.
You can learn how dvc exp run uses custom Git refs to track experiments in
this blog post and you can see a quick
technical overview in
the docs here.
What is a good way to debug DVC stages in VSCode?
A great question here from @quarkquark!
You can debug in VSCode by following the steps below:
- Install the
debugpypackage. - Navigate to
"Run and Debug" > "Remote Attach" > localhost > someport. - In a terminal in VSCode,
python -m debugpy --listen someport --wait-for-client -m dvc mycommand
This should help you debug the stages in your pipeline in the IDE and you can find more details here.
Is there a way to list what files (and ideally additional info like location, MD5, etc) are within a directory tracked by DVC?
Thanks for asking @CarsonM!
You should be able to use DVC to list the directory contents of your DVC remotes without pulling the repo. Here's an example of the command you can run:
$ dvc list https://github.com/iterative/dataset-registry/ fashion-mnist/rawIf we have multiple datasets, is it recommended to have 1 remote per dataset or to have 1 remote and let DVC handle the paths?
This is a really interesting question from @BrownZ!
It really depends on your use case. Separated remotes might be useful if you want to have granular control over permissions for each dataset.
In general, we would suggest a single remote and setting up a data registry to handle the different datasets through DVC.
Is there a mailing list for subscribing to CML releases?
It's awesome community members like @pria want to keep up with our releases!
You can follow all of our releases via GitHub notifications. You can browse
release notes at https://github.com/iterative/cml/releases. You can also
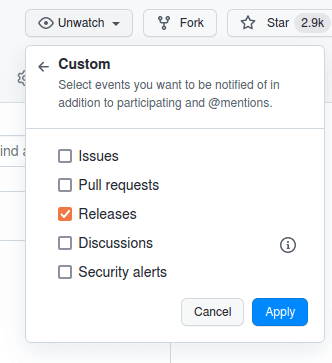
subscribe to release updates by clicking the Watch button in the top-right,
navigating to Custom, and checking the Releases option.
Does cml-send-comment work for azure devops repositories?
Thanks for the question @1cybersheep1!
Currently, the supported Source Code Management tools are GitHub, GitLab, and Bitbucket. Other SCMs may be a part of the roadmap later on.
If my model is training on a self-hosted, local runner, and I already have a shared DVC cache set up on the same machine, is there a good way for my GitHub workflow to access that cache instead of having to redownload it all from cloud storage?
Excellent question from @luke_imm!
In GitHub, you can mount volumes to your container, but you have to declare them within the workflow YAML
Join us in Discord to get all your DVC and CML questions answered!