AITA for making this? A public dataset of Reddit posts about moral dilemmas
Delve into an open natural language dataset of posts about moral dilemmas from r/AmItheAsshole. Use this dataset for whatever you want- here's how to get it and start playing.





In data science, we frequently deal with classification problems like, is this Yelp reviewer unhappy with their brunch? Is this email begging me to claim my long-lost inheritance spam? Does this movie critic have a positive opinion of Cats?
Perhaps we should also consider the fundamental introspective matter of, am I maybe being a bit of an asshole?
I want to share a dataset of collected moral dilemmas shared on Reddit, as well as the judgments handed down by a jury of Redditors. The wellspring of this data is the r/AmItheAsshole subreddit, one of the natural wonders of the digital world. In this article, I'll show you what's in the dataset, how to get it, and some things you can do to move the frontiers of Asshole research forward.
What makes an Asshole?
r/AmItheAsshole is a semi-structured online forum that’s the internet’s closest approximation of a judicial system. In this corner of the web, citizens post situations from their lives and Redditors vote to decide if the writer has acted as The Asshole or not. For example:
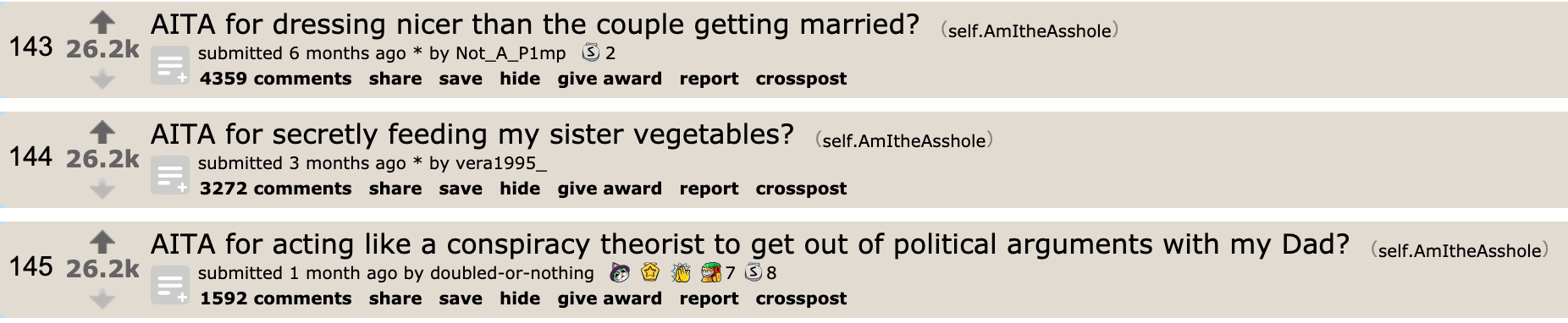
Without bringing any code into the picture, it’s intuitive to think of each new post as a classification task for the subreddit. Formally, we could think of the subreddit as executing a function f such that

Of course, finding f won’t be trivial. To be frank, I’m not positive how well we could hope to forecast the rulings of the subreddit. A lot of posts are not easy for me to decide- like,

There are also many times I find myself disagreeing with the subreddit’s verdict. All this is to say, I don’t think it’s obvious how well a given human would do on the task of predicting whether Redditors find someone an Asshole. Nor is it clear how well we could ever hope for a machine to do approximating their judgment.
It seems fun to try, though. It helps that the data is plentiful: because the subreddit is popular and well-moderated, there’s an especially strong volume of high-quality content (re: on-topic and appropriately formatted) being posted daily.
Building the dataset
I pulled content from r/AmITheAsshole dating from the first post in 2012 to January 1, 2020 using the pushshift.io API to get post ids and scores, followed by Reddit’s API (praw) to get post content and meta-data. Using a similar standard as OpenAI for trawling Reddit, I collected text from posts with scores of 3 or more only for quality control. This cut the number of posts from ~355K to ~111K. Each data point contains an official id code, timestamp, post title, post text, verdict, score, and comment count; usernames are not included. The scraping and cleaning code is available in the project GitHub repo. For simplicity on the first iteration of this problem, I didn’t scrape post comments, which can number in the thousands for popular posts. But, should sufficient interest arise, I’d consider adding them to the dataset in some form.
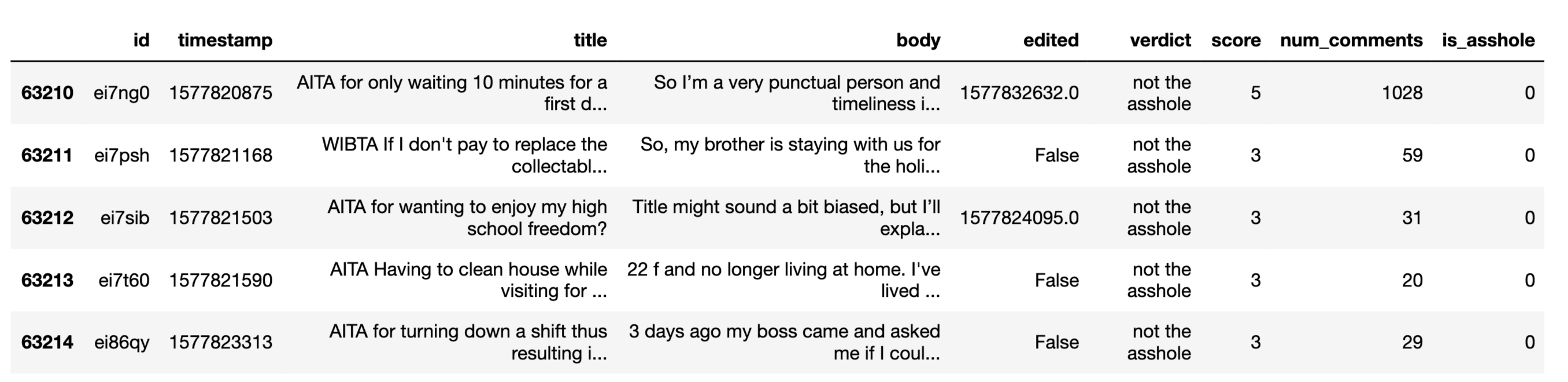
To focus on the task of classifying posts, I did some light cleaning: I removed posts in which the body of the text was redacted (surprisingly common) or blank, and attempted to remove edits where the author had clearly given away the verdict (e.g., an edit that says, “Update: You’re right, I was the asshole.”). There were also verdicts that only occurred once (“cheap asshole”, “Crouching Liar; hidden asshole”, “the pizza is the asshole”), so I restricted the dataset to posts with standard verdicts. This left ~63K points. Below is a sample of the resulting dataframe:
The dataset is a snapshot of the subreddit in its current state, but the subreddit is certain to change over time as new content gets added. In the interest of having the most comprehensive dataset about being an asshole ever collected, I’m planning to update this dataset monthly with new posts.
How to get the dataset
Since this dataset will be updated regularly, we’re using git and DVC to
package, version, and release it. The data itself is stored in an S3 bucket, and
you can use DVC to import the data to your workspace. If you haven't already
you'll need to install DVC; one of the simplest
ways is pip install dvc.
Say you have a directory on your local machine where you plan to build some analysis scripts. Simply run
$ dvc get https://github.com/iterative/aita_dataset \
aita_clean.csvThis will download a .csv dataset into your local directory, corresponding to
the cleaned version. If you wanted the raw dataset, you would substitute
aita_raw.csv for aita_clean.csv.
Because the dataset is >100 MB, I’ve created a git branch (called “lightweight”) with 10,000 randomly sampled (cleaned) data points for quick-and-dirty experimentation that won’t occupy all your laptop’s memory. To download only this smaller dataset, run
$ dvc get --rev lightweight \
https://github.com/iterative/aita_dataset \
aita_clean.csvA quick look at the data
Let’s take a flyover look at the dataset so far. The code to make the following visuals and results is available on GitHub. First, here’s a frequency plot for how common different verdicts are on the subreddit. In addition to “Asshole” and “Not the Asshole”, there are two additional rulings: “Everybody Sucks” and “No Assholes Here”.

In general agreement with an analysis by Nathan Cunn, the majority of posts are deemed “Not the Asshole” or “No Assholes Here”. If you are posting on r/AmITheAsshole, you are probably not the asshole.
Next, I attempted a very basic classifier, logistic regression using 1-gram frequencies (i.e., the frequency of word occurences in post titles and bodies) as features. This is intended to give a baseline for what kind of performance any future modeling efforts should beat. Because of the strong class imbalance, I used SMOTE to oversample Asshole posts. And, for simplicity, I binarized the category labels:
| Verdict | Label |
|---|---|
| Asshole | 1 |
| Everyone Sucks | 1 |
| Not the Asshole | 0 |
| No Assholes Here | 0 |
With 5-fold cross-validation, this classifier performed above-chance but modestly: accuracy was 62.0% +/- 0.005 (95% confidence interval). Curiously, the only other classifier attempt I could find online reported 61% accuracy on held-out data using the much more powerful BERT architecture. Considering that logistic regression has zero hidden layers, and our features discard sequential information entirely, we’re doing quite well! Although I can’t be certain, I’m curious how much the discrepancy comes down to dataset size: the previous effort with BERT appears to be trained on ~30K posts.
Seeing that logistic regression on word counts doesn’t produce total garbage, I looked at which words were predictive of class using the chi-squared test. The top five informative words were mom, wife, mother, edit, and dad (looks like Assholes go back to edit their posts). Since familial relationships featured prominently, I estimated the log odds ratio of being voted Asshole (versus Not the Asshole) if your post mentions a mom, dad, girlfriend/wife or boyfriend/husband. Roughly, the log odds ratio represents the difference in probability of a keyword occurring in Asshole posts compared to Not-Asshole posts.

For reference, the log odd ratios are computed with base 2; a score of 1 means that Asshole posts are twice as likely to contain the keyword as Not the Asshole posts. So keep in mind that the effect sizes we’re detecting, although almost certainly non-zero, are still fairly small.
There seems to be a slight anti-parent trend, with Redditors being more likely to absolve authors who mention a mom or dad. Only mentioning a female romantic partner (wife/girlfriend) was associated with a greater likelihood of being voted the Asshole. This surprised me. My unsubstantiated guess about the gender difference in mentioning romantic partners is that women may be particularly likely to question themselves when they act assertively in a relationship. If this were the case, we might find an especially high proportion of uncontroversial “Not the Asshole” posts from heterosexual women asking about situations with their male partners.
How to get more data
As I said earlier, the plan is to grow the dataset over time. I’ve just run a
new scrape for posts from January 1-31, 2020 and am adding them to the public
dataset now. To check for a new release, you can re-run the dvc get command
you used to grab the dataset.
If you’re serious about taking on a project such as, say, building a classifier
that beats our state of the art, word-count-based, logistic regression model,
I’d like to recommend a better way to integrate the dataset into your workflow:
dvc import. dvc import is like dvc get, but it preserves a link to the
hosted data set. This is desirable if you might iterate through several
experiments in the search for the right architecture, for example, or think
you’ll want to re-train a model . To get the dataset the first time, you’ll run:
$ git init
$ dvc init
$ dvc import https://github.com/iterative/aita_dataset \
aita_clean.csvThen, because the dataset in your workspace is linked to our dataset repository, you can update it by simply running:
$ dvc update aita_clean.csvAn additional benefit of codifying the link between your copy of the dataset and ours is that you can track the form of the dataset you used at different points in your project development. You can jump back and forth through the project history then, not only to previous versions of code but also to versions of (specifically, links to) data. For example, you could roll back the state of the project to before you updated the dataset and re-run your classifier:
$ git log --oneline
58e28a5 retrain logistic reg
6a44161 update aita dataset
0de4fc3 try logistic regression classifier
a266f15 get aita dataset
55031b0 first commit
$ git checkout 0de4fc3
$ dvc checkout
$ python train_classifier.pyOh, and one more note: you can always use dvc get and dvc import to grab an
older version of the dataset using the tags associated with each release. The
current release is v.20.1 and the original release is v.20.0- the numeric codes
correspond to the year and month.
$ dvc get --rev v.20.0 \
https://github.com/iterative/aita_dataset aita_clean.csvWhat’s next
I hope that sharing this evolving dataset invites some curiosity, because a lot of questions come to mind:
- Can you beat our classifier that predicts how the subreddit will rule?
- Is verdict even the most interesting outcome to predict? For example, developer Scott Ratigan created a tool to estimate weighted scores for each post based on the comments (e.g., 75% Asshole, 25% Not the Asshole). What metrics might invite deeper questions?
- Can you identify sentences or phrases that are most informative about the verdict Redditors reach?
- Do voting patterns systematically differ by topic of discussion?
- How reliable are verdicts? When a very similar situation is posted multiple times, do Redditors usually vote the same way?
- Is the subreddit’s posting and voting behavior changing over time?
- Can you formulate any testable hypotheses based on this survey of the subreddit’s demographics
- How often do non-Redditors agree with the subreddit? Under what circumstances might they tend to disagree?
I expect that leaning into the particulars of the dataset- thinking about how the format influences the content, and how a subreddit might select for participants that don’t fully represent the population at large- will lead to more interesting questions than, say, aiming to forecast something about morality in general. To put it another way, the data’s not unbiased- so maybe try to learn something about those biases.
If you make something with this dataset, please share- perhaps we can form an international Asshole research collective, or at least keep each other appraised of findings. And of course, reach out if you encounter any difficulties or probable errors (you can file issues on the GitHub repo)!
Lastly, please stay tuned for more releases- there are hundreds of new posts every day. The biggest asshole may still be out there.
More resources
You may want to check out a few more efforts to get at r/AmItheAsshole from a data-scientific perspective, including topic modeling, visualizing voting patterns and growth of the subreddit, and classification with deep learning. With a dataset this rich, there’s much more to be investigated, including continuing to refine these existing methods. And there’s almost certainly room to push the state of the art in asshole detection!
If you're interested in learning more about using Reddit data, check out pushshift.io, a database that contains basically all of Reddit's content (so why make this dataset? I wanted to remove some of the barriers to analyzing text from r/AmItheAsshole by providing an already-processed and cleaned version of the data that can be downloaded with a line of code; pushshift takes some work). You might use pushshift's API and/or praw to augment this dataset in some way- perhaps to compare activity in this subreddit with another, or broader patterns on Reddit.