Automate Your ML Pipeline: Combining Airflow, DVC, and CML for a Seamless Batch Scoring Experience
In this tutorial, we'll guide you through the process of setting up an end-to-end experimentation, training, and production infrastructure for batch scoring applications. By leveraging popular software engineering tools like Git and Gitlab, alongside data engineering powerhouse Airflow, with the reproducibility and automation strengths of DVC and CML, you will have one solid pipeline!





Companies in Banking, Telecom, Retail, and other industries operate the enormous size of data to generate insights and gain value. Batch scoring is a common way to operate machine learning applications for such companies. It helps to run ML training and inference (scoring) jobs that operate with large amounts of data. This post covers topics around the design, tools, and implementation of ML applications for batch scoring scenarios with Airflow.
What is batch scoring?
In machine learning, scoring is the process of applying a trained model to a new dataset in an attempt to get practical predictions. Batch scoring is the way to score (get predictions) for large datasets that are collected over some period of time before being passed to the model. It is the most effective scoring pattern when the model’s decisions don’t have to be implemented immediately. For example, a CRM Department in Retail Banking may apply ML models to a batch of active customers to determine which are most likely to buy a new credit product next month. Other application examples:
-
Marketing Communication Optimization: effectively identifying customers who are looking for new financial products and services, and then optimizing marketing communication, is a perfect application for AI. This use case includes not only identifying customers with a propensity to buy new products, but also customers at risk of churning.
-
Pricing Optimization: personalization of banking services requires monitoring the marketplace dynamically to provide competitive prices for existing and new customers.
-
Next Best Action (NBA): this is a promising customer-centric approach to optimize multiple different actions that could be taken for a specific customer through multiple communication channels.
Goals for this post
This post shares an approach to solve 3 tasks in batch scoring applications:
-
Build an ML pipeline to train a model.
-
Setup a
trainCI job to run a model training at scale. -
Setup a
deployCI job to deliver the inference (scoring) pipeline to an Airflow cluster.
How to reproduce
Code examples are stored in two repositories:
-
home_credit_default contains an end-to-end solution for a batch scoring application with Airflow
-
airflow-cluster contains configuration for Airflow and other services
Fork the home_credit_default repository if you'd like to replicate our steps and deploy your own batch-scoring application with Airflow and DVC. Keep in mind that you'll need the setup and to configure the following:
-
GitLab account and Personal Access Token.
-
pipand Docker installed locally
The repository also contains code for Airflow DAGs, which can be found in the
dags/ directory. A separate
airflow-cluster
repository is used to set up and run the Airflow cluster.
Design ML pipelines with DVC
Machine Learning experiment pipelines for batch-scoring applications typically involve the following steps:
-
Data preparation: The first step is to clean, pre-process, and transform the data into a format that can be used for training machine learning models.
-
Feature engineering: In this step, relevant features are extracted or created from the data and transformed into a format that can be used for training machine learning models.
-
Model selection and training: Next, multiple machine learning models are selected and trained using the prepared data.
-
Model evaluation: The trained models are then evaluated to determine their accuracy and performance on new data.
By following these steps, the pipeline provides a systematic approach to experimenting with different machine learning models, including feature engineering, and selecting the best one for deployment.
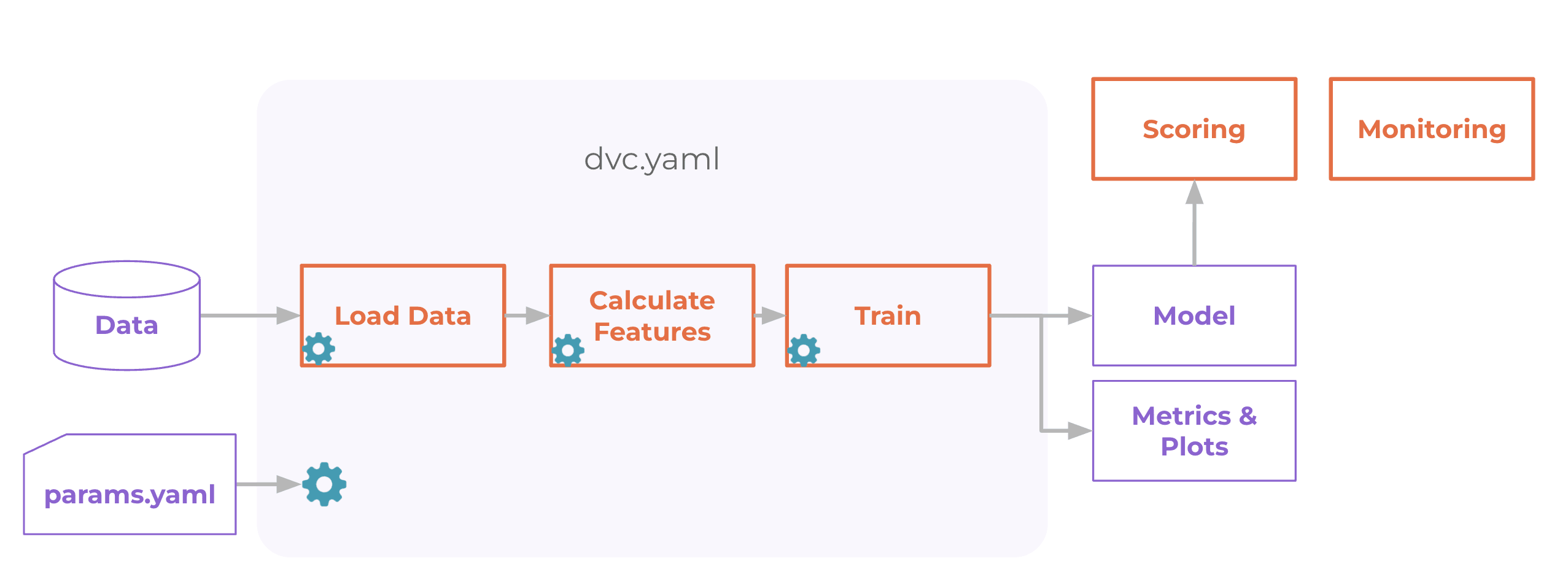
DVC is a great tool that can help to automate such kinds of
ML pipelines. For the purpose of this tutorial, the DVC pipeline consists of
five stages (see dvc.yaml in
the example repo):
-
Load Data (
load_data) -
Calculate features for
bureau.csvdata (extract_features_bureau) -
Calculate features for
application.csvdata (extract_features_application) -
Join features (
join_features) -
Train and save a model (
train)
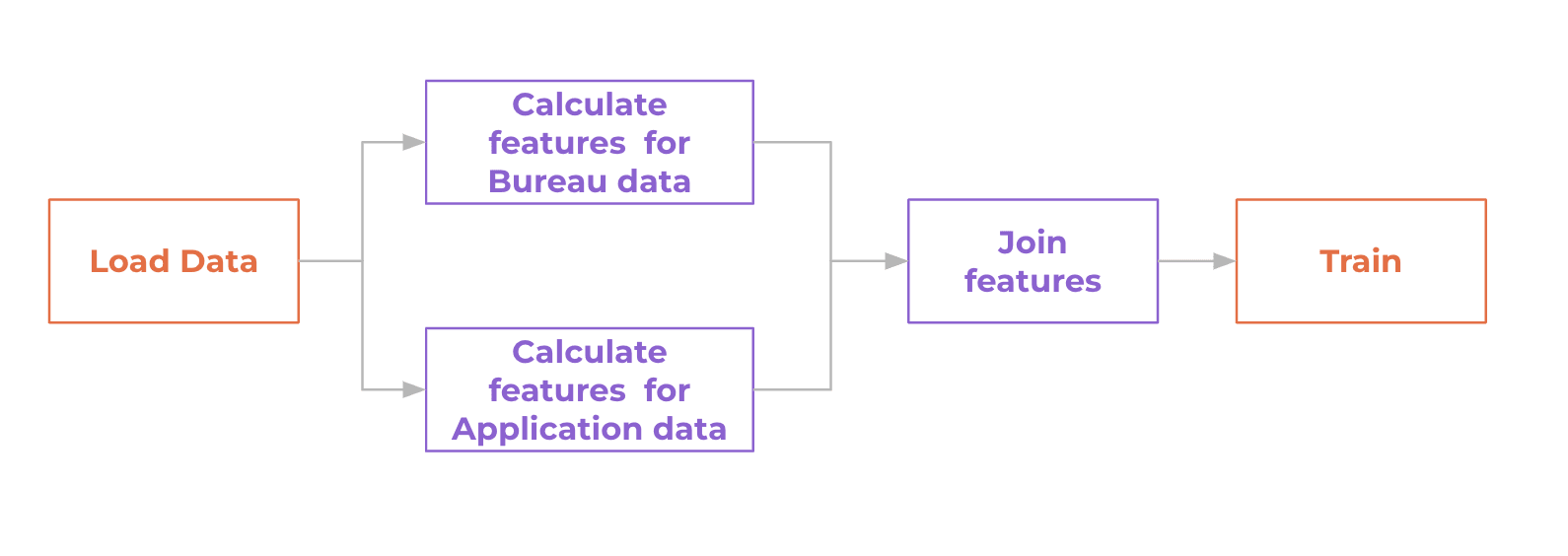
The diagram below visualizes dependencies between stages of the DVC pipeline.
For such patterns, DVC helps automatically track changes and optimize the time
to run the pipeline. For example, if you iteratively improve only code to
calculate features for Bureau data, DVC will only rerun 3 stages:
extract_features_bureau, join_features, and train. DVC with skip running
load data and extract_features_application because these steps did not
change, saving a substantial amount of time.
After we prepare the configuration for the ML pipeline, DVC helps to run a new model training experiment with a simple single command:
$ dvc exp runOr, if you want to update the configuration of the params.yaml file and set a
specific name of the experiment you may run a command:
$ dvc exp run -n <NAME> [--set-param <param_name>=<param_value>]Train model at scale with Studio and CML
In a common scenario, batch-scoring applications require a large amount of data stored in remote storage. Data Scientists run ML experiments on a local (dev) machine (e.g. laptop) using a sample of the data. After the model and hyperparameters configuration are found, an additional training run on the full dataset is required. Sometimes, the final model training is run on a different high-performance machine. Results for the ML experiments should be stored and accessible for the next analysis, following experiments, and any team members that need to review them.
Continuous Integration (CI) workflow
Designing a CI (Continuous Integration) job to run model training at scale involves the following steps:
-
Environment setup: Create a reproducible environment for model training by using virtual machines or containers. GitLab and CML help us preparing and provisioning an environment for the training job.
-
Automated build: Set up an automated build process that triggers a build every time code is committed to the repository. We use GitLab CI configuration to automate building a Docker image and run tests for the code.
-
Parallel processing: Utilize parallel processing to run multiple model training jobs in parallel. This reduces the time required to train the model and can be accomplished using tools like Dask or Ray. In this example, we don’t use these tools.
-
Training: Make sure that the model training pipeline can scale to handle large amounts of data and processing power. As a result of the training job, a new model is saved. CML may help to set up and use cloud computing resources or by using high-performance computing systems.
GitLab's Continuous Integration (CI) pipeline configuration for this post
example is stored in the
.gitlab-ci.yml file.
It specifies different stages of the pipeline including building an image,
testing the code, training a model, and deploying Airflow DAGs. The image below
provides a graphical representation of this pipeline.
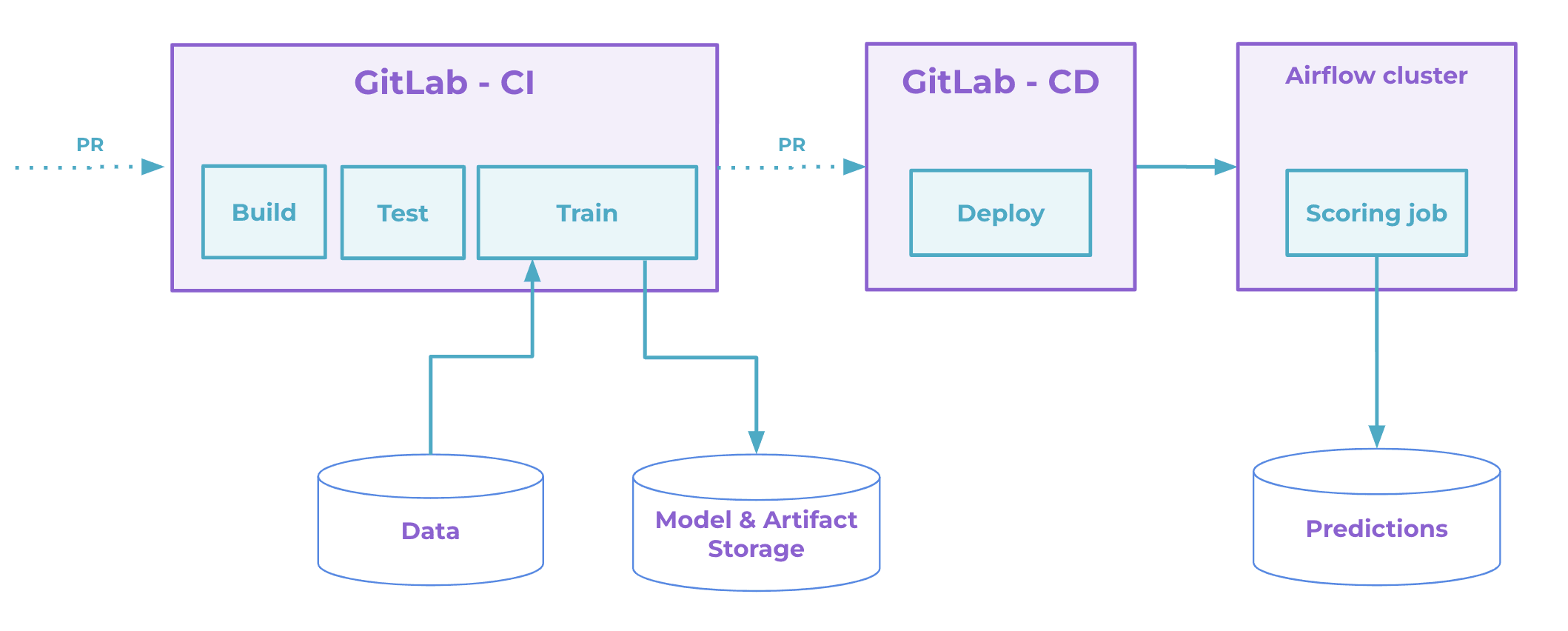
-
The GitLab repository triggers the CI pipeline as soon as new code or parameters updates are committed to the repository. This runs
build,test, andtrainCI jobs. Thetrainjob runs a model training on a full dataset on a remote machine (or cloud), generates model training reports, and creates a PR in the GitLab repo. -
Merging (accepting a pull/merge request) the experiment results into the
mainbranch triggers thedeployjob. -
Every month, Airflow runs
scoringjobs to generate predictions (scores) for all clients on new data. Generated predictions are stored in the prediction database or files.
Setup train job with GitLab CI and CML
For this post’s example the training job is triggered on creating a new Merge
Request into the main branch or, if the Git commit message (commit to any
branch) contains the [exp] tag. This configuration allows us to achieve two
goals:
-
We may define whether new code (or params) changes need to trigger a new experiment, or if it’s just a minor update (e.g. update the documentation in README) there is no need to run a new experiment,
-
We ensure that every merge into the
mainbranch is linked to the latest model.
An example of the train job configuration is presented below. There are three
main steps in the script there:
-
Run a new experiment on a full-scale dataset with
dvc exp run -
Prepare the
report.mdfile with metrics and plots, -
Publish the
report.mdcontent to the Merge Request (Pull Request) message in GitLab (using CML).
train:
...
rules:
- if: $CI_MERGE_REQUEST_TARGET_BRANCH_NAME == "main" || $CI_COMMIT_MESSAGE =~ /\[exp\]/
image: ${PROJECT_IMAGE}
script:
- ...
- dvc exp run --pull -S load_data.sample_size=1.0
- |
echo "# Metrics" >> report.md
echo "## Experiment metrics" >> report.md
dvc metrics show --show-md >> report.md
...
echo "## Plot train lift curve " >> report.md
echo '' >> report.md
- cml pr create . --md >> report.md
- cml comment create --target=commit report.mdRun ML experiments with Iterative Studio
The proposed CI pipeline makes it possible to implement a development process that:
-
Automates the launch of experiments with training models when the code changes.
-
Links the change in versions of the code and artifacts (models, data).
-
Makes the development more straightforward and manageable.
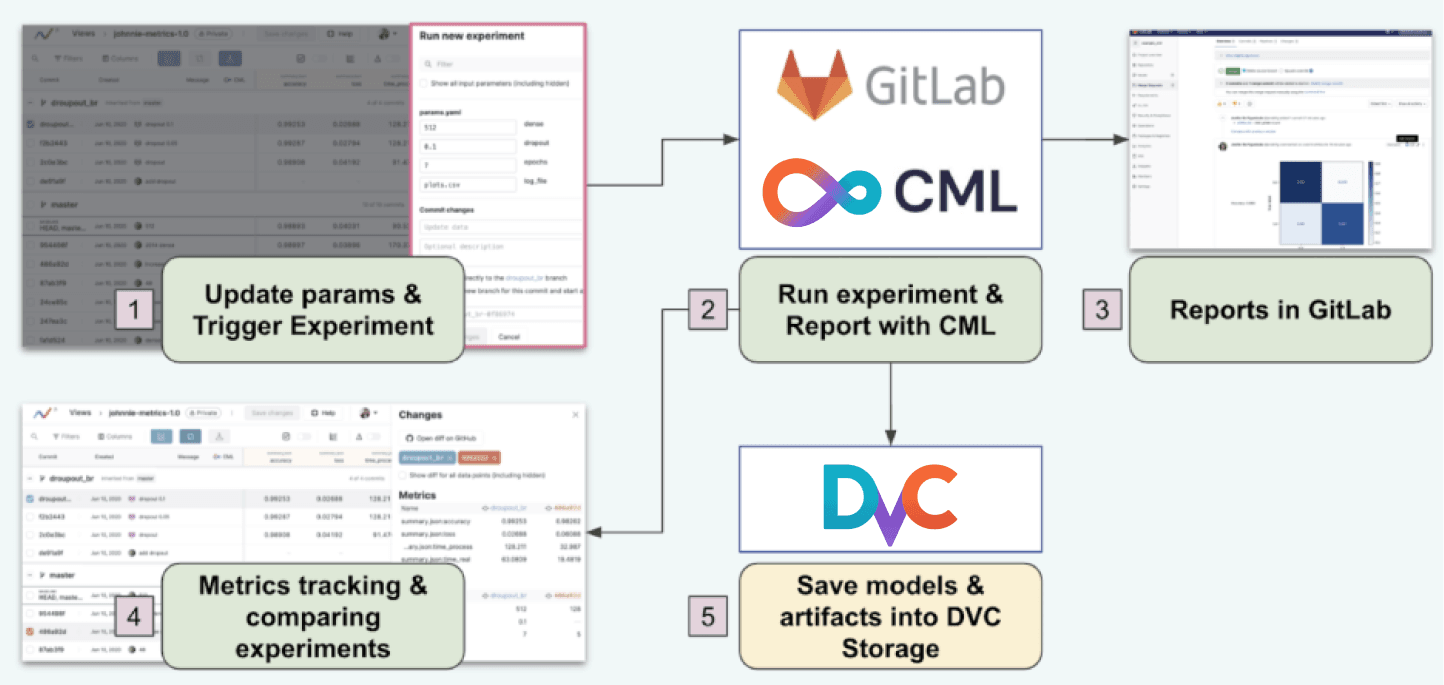
Moreover, it enables Iterative Studio to run new experiments from the UI.
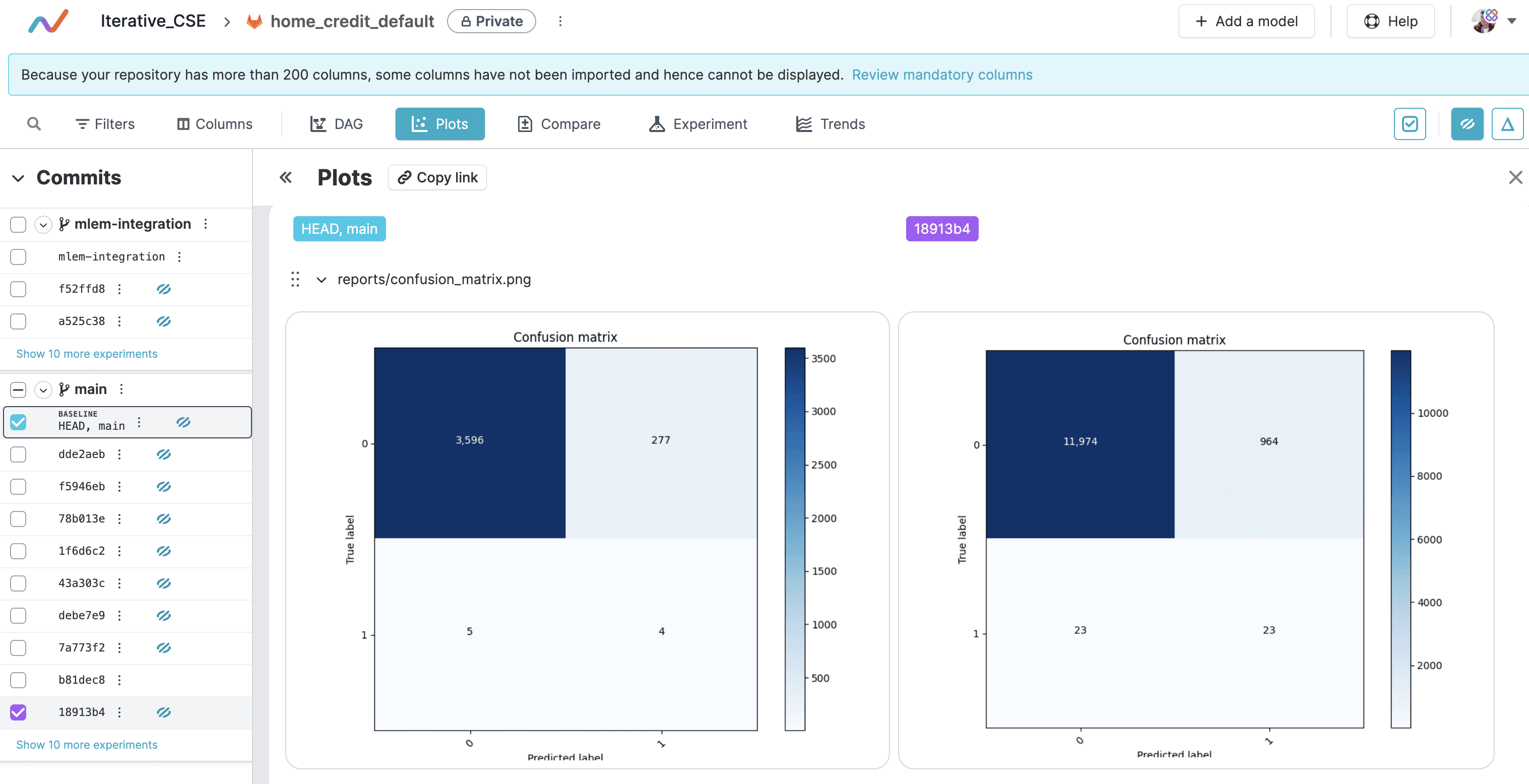
The experimenting process of Iterative Studio is very simple! (See diagram below).
-
In the first step (1), we update the experiment configuration and trigger running a new experiment. This functionality is available in the standard package of the Iterative Studio.
-
Then (2) the configured GitLab CI pipeline launches the experiment job running.
-
After the job completes, CML publishes the experiment report to GitLab commit message (3). Iterative Studio is constantly monitoring the project repository for updates.
-
As soon as the repo changes, Iterative Studio updates tracking files in the UI (4). Data Scientists can compare experiment metrics and plots.
-
Also, DVC stores the updated versions of a model and artifacts to DVC Storage (5).
After the experiment completes Iterative Studio helps to visualize parameters, metrics, and plots. Users may compare experiments, run new ones, and share with colleagues.
Deploy scoring pipeline
A batch scoring inference pipeline in machine learning is a series of steps that are executed in a specific order to process a large amount of data and generate predictions based on a pre-trained model. It typically includes the following steps:
-
Input data preparation: This step involves cleaning, transforming, and preprocessing the input data so that it can be fed into the model for prediction. Feature engineering can be a part of this step.
-
Model loading: The pre-trained model is loaded into memory, usually from storage or a database, so that it can be used for predictions.
-
Inference: The input data is passed through the model to generate predictions. This is done in a batch-wise manner, where a large amount of data is processed in one go to reduce the overhead of repetitively loading the model.
-
Post-processing: This step involves any additional processing of the prediction results, such as normalization, thresholding, or aggregation, before they are written to an output file or database.
-
Saving predictions: Finally, the prediction results are saved to a file or database for further analysis or use. This can be done in various formats, such as CSV, JSON, or binary.
The pipeline can be implemented using a variety of tools and technologies such as Apache Airflow, Apache Spark, or even custom scripts. The key aspect of a scoring pipeline is that it is automated, efficient, and scalable, making it possible to score large volumes of data in a timely and consistent manner.
Because of the large number of pre- and post-processing tasks, including checking for data sources updates, the typical scenario needs to deploy a scoring pipeline, not a model.
Batch scoring inference pipeline with Airflow
In this example, we implement an inference pipeline using Apache Airflow. Airflow helps to schedule and run pipelines (DAG) for various data engineering and machine learning purposes. DAG is a Directed Acyclic Graph that describes an order of computational Tasks (jobs) to run. The basics of the Airflow pipeline definition can be found here.
We store Airflow DAGs in the dags/ directory in the same repository as our ML
pipeline.
Let’s go a bit deeper into the Airflow DAG dags/scoring.py to find out how DVC
is used there! This DAG is designed to be run every 5th day of the month to
calculate predictions and save them into a .csv file.
The DAG performs the following steps:
-
It creates a temporary directory for the local repository (
create_tmp_dirtask). -
It clones the repository specified in the
project_argsargument (clonetask). -
It runs the scoring script from the cloned repository and saves predictions (
run_scoringtask). -
Finally, it removes the temporary repository directory (
cleantask).
For the purposes of this post, we are most interested in the run_scoring task!
The task 'run_scoring' is a BashOperator in Apache Airflow. It performs the
following actions:
-
Runs the
dvc fetchcommand to fetch the latest version of the artifacts and model to be used for inference. -
Runs the
dvc checkoutcommand to check out the latest version of the data. -
Runs a python script located at
src/stages/scoring.pywith the following command line arguments:-
--configspecifies the path to the parameters file in YAML format, -
--scoring-datespecifies the date for which the scoring should be performed, -
--storage-pathspecifies the location of the storage.
-
run_scoring = BashOperator(
task_id='run_scoring',
bash_command=f'''
cd {project_args.get('dag_run_dir')} && \
export PYTHONPATH=. k&& \
dvc fetch && \
dvc checkout && \
python src/stages/scoring.py \
--config=params.yaml \
--scoring-date={{{{ first_day_of_month(ds) }}}} \
--storage-path={project_args.get('storage_path')} \Therefore, this example shows the deployment of the Airflow DAGs, and DVC helps to fetch the latest model to be used for inference. This is awesome!
Setup CI job deploy
There are various strategies for delivering scoring DAG to the Airflow
cluster. In this example, the GitLab CI pipeline pushes (copies) DAG files from
the repo to the Airflow home directory (specified by ${AIRFLOW_HOME}) and
activates it.
The deploy_dags CI job configuration looks like this:
deploy_dags:
stage: deploy
...
script:
- |
export DAGS_FOLDER=${AIRFLOW_HOME}/dags/${PROJECT_FOLDER}
# Create ${DAGS_FOLDER}
rm -rf ${DAGS_FOLDER} && mkdir -p ${DAGS_FOLDER}
# Copy content of folder ./dags to ${DAGS_FOLDER} directory
cp -r dags/* ${DAGS_FOLDER}
echo "Airflow DAGs copied to ${DAGS_FOLDER}"This simple example is for demonstration purposes, but it works as a proof-of-concept for DVC-Airflow-Studio integration for batch scoring applications.
Results
The proposed approach demonstrates how DVC, CML, and Iterative Studio may help in batch scoring applications at the experimentation and production phases. Solutions discussed in this post may benefit similar use cases in a few ways:
-
Help with system design and tools integration.
-
Automate ML experiments.
-
Increasing speed of Proof-Of-Concept (POC) and Operationalization (MLOps) stages.
-
Saving time and money for similar projects.
Specifically, DVC and Iterative Studio can benefit batch scoring Applications by:
-
Enabling regulatory compliance and auditability. Iterative Studio offers a robust approach for data usage tracking, keeping, and versioning data and configurations used for model training and prediction. Models are developed in a robust environment allowing us to link code, data, and configs for reproducible experiments and ensure auditability in the event of a compliance audit.
-
Run machine learning experiments, with or without coding. Iterative Studio offers a user-friendly UI for analysts and data scientists to create a new experiment, change the configuration, and run with a one-button-click.
-
Access versioned models during the CI/CD process and use them to run a scoring job with Airflow.
Have something great to say about our tools? We'd love to hear it! Head to this page to record or write a Testimonial! Join our Wall of Love ❤️
Do you have any use case questions or need support? Join us in Discord!
Head to the DVC Forum to discuss your ideas and best practices.