Building a GitOps ML Model Registry with DVC and GTO
A model registry is a tool to catalog ML models and their versions. Models from your data science projects can be discovered, tested, shared, deployed, and audited from there. Learn how to build a model registry in a DVC Git repo without involving any extra services, integrations and APIs.





Header image generated by Dall-E 2
Machine Learning is iterative in its nature. Similar to developing software,
you’re going to have many different versions of your models, improving them step
by step (such as v0.1.0, v0.2.0, etc). To keep track of model development,
trigger checks, and deployments, and know which versions are in production and
which are stuck in staging (both right now and retrospectively), ML specialists
organize models' lifecycles using Model Registries.
The Pluses and Minuses of Model Registries
While model registries solve operational issues, many solutions come at a cost. Model Registries often introduce a separate software stack that must be learned, integrated with, and maintained. For example, if you keep your model training code in Git, train your models with CI/CD, and use CI/CD to deploy them, introducing a separate service in the middle of the process breaks the flow and forces you to leave your code versioning ecosystem (Git + GitHub for example). This happens when we add more and more systems and services that all try to be the center of attention. A good example is working with MLFlow or SageMaker as a model registry - there’s a feeling it’s always “in the way” of the Git-based development workflow.
Our Git-based Solution to Model Registry
To help you with that, we developed a CLI tool named
GTO. The tool is very simple - it organizes
Model Registry in your Git repo using Git tags and a file called
artifacts.yaml. Welcome to this short tutorial on how to do just that - and
it's simpler than you might think.
Before we start, let’s take a look at Studio Model Registry, which provides a nice UI dashboard on top of GTO-managed registries:

v2.0.1 or v1.0.1) and
stage assignments (like dev, prod, and staging) done by team members
(assigning v1.0.0 to dev signals the version is ready to be deployed to the
dev environment and can trigger that deployment directly).
Take a look around in our demo Model Registry to get a feel for Iterative Studio's Model Registry features.
GTO provides a simplistic representation of the same from CLI, thus accessible from a terminal and friendly for a developer:
$ gto show --repo https://github.com/iterative/demo-bank-customer-churn
╒════════════════════╤══════════╤════════╤═════════╤══════════╕
│ name │ latest │ #dev │ #prod │ #stage │
╞════════════════════╪══════════╪════════╪═════════╪══════════╡
│ randomforest-model │ v2.0.0 │ v2.0.0 │ v1.0.0 │ - │
│ xgboost-model │ v1.0.1 │ - │ - │ v1.0.0 │
│ lightgbm-model │ v2.0.3 │ v2.0.3 │ v2.0.0 │ v2.0.0 │
╘════════════════════╧══════════╧════════╧═════════╧══════════╛Notice that GTO works with a single repo at a time - that’s why we need to
specify the --repo argument, while Studio aggregates your models from multiple
projects and repositories you add to it.
For this tutorial, we'll pick a simple project with no models registered yet, to demonstrate adding a model registry on top of an existing ML project. We'll take https://github.com/iterative/example-get-started, which is an example DVC project. We won’t get into details about DVC, but if you’re new to it, you can check out DVC Get Started. Revisit the example project before we start to get a quick picture of it if you wish.
The project trains a natural language processing (NLP) binary classifier
predicting tags for a given StackOverflow question. It uses DVC Pipelines to
connect raw text preprocessing and model training, producing an ML model stored
in the model.pkl. The main branch has a model version we can consider as the
first version, while the branch try-large-dataset is a promising experiment
that we’d like to mark as the second version and assign to the dev stage to
trigger a deployment.
To start, we need to
fork the repo, since
we’re going to make some changes to it. Note that you need to uncheck "Copy the
main branch only" because we'll be using the try-large-dataset branch as
well:

To use GTO from CLI, we'll set up a Python virtual environment:
$ python -m venv .venv
$ source .venv/bin/activate
$ pip install gtoTo remove some friction, we won’t clone the repo locally. This will save us from
running commit and push to update the remote repo, and GTO will do that for
us.
Registering a model version
In the repo, we have an already trained ML model saved as model.pkl. The file
itself resides in an AWS S3 bucket and is tracked with DVC. One of the versions
of that model can be found in the HEAD of the main branch. Let’s register the
very first version of it - v0.0.1. Since we’ll be using
our remote repo many times here, we'll set a shell var $REPO to store the URL.
$ REPO=https://github.com/{user}/example-get-started
$ gto register classifier --repo $REPO
Created git tag '[email protected]' that registers a version
Running `git push origin [email protected]`
Successfully pushed git tag [email protected] on remote.Now the model is called classifier in our registry and the v0.0.1 version is
registered in the tip of the main branch.
Since the repo we're working with is a remote one, GTO pushes a tag to the repo
automatically. With a local repo, you will need to run git push yourself
(although you can make GTO do that by providing a --push argument). This
workflow should be familiar to DVC and Git users - making changes locally and
then pushing them to remote with an additional command.
Now we can see the model dashboard of our registry:
$ gto show --repo $REPO
╒════════════╤══════════╕
│ name │ latest │
╞════════════╪══════════╡
│ classifier │ v0.0.1 │
╘════════════╧══════════╛Remember, that we only see a single classifier model because GTO works with a
single repo and the models we’ve seen above were from another repository (notice
the --repo argument).
A common case is to use a model registry as a source of truth to pull models for
experimentation locally or in CI for deployments. Note that for now we manually
provide the path to the model (model.pkl) and Git revision to use
([email protected]). We’ll learn how to dynamically set them up using GTO in
the next sections.
$ dvc get $REPO model.pkl --rev [email protected] -o model.pklAdding optional model metadata
To skip hardcoding a model path in our scripts or writing model description
somewhere in the notebook, we need to store metadata about the model in the repo
itself. Unlike the Git tag, we created to register a version, GTO stores
metadata in a file, which requires us to create a commit. This allows us to have
different paths or descriptions in different commits and branches, which can be
useful if you’ll be updating your model significantly or changing the structure
of your repo. Since the model is not annotated right now, let’s add that
information to the new model version in the try-large-dataset branch that
increased ROC AUC of the model.
Later we can merge this to main to update the annotation there:
$ gto annotate classifier\
--repo $REPO \
--rev try-large-dataset \
--path model.pkl \
--description "Simple text classification model"
--type model
Updated `artifacts.yaml`
Running `git commit` and `git push`
Successfully pushed a new commit to remote.This creates an artifacts.yaml file with the following contents in the
try-large-dataset branch:
classifier:
path: model.pkl
description: Simple text classification model
type: modelRegistering another version
Since GTO allows you to build any kind of registry, including dataset registry,
model registry, or a mix of both, to distinguish between different artifact
types (e.g. a dataset and a model), it’s good to specify type while
annotating. This will also hint to Studio that classifier is a model so
Studio could display it in Studio Model Registry.
Let’s register a new version in the try-large-dataset branch:
$ gto register classifier \
--repo $REPO \
--rev try-large-dataset
Created git tag '[email protected]' that registers version
Running `git push origin [email protected]`
Successfully pushed git tag [email protected] on remote.Checking the updated model dashboard:
$ gto show --repo $REPO
╒════════════╤══════════╕
│ name │ latest │
╞════════════╪══════════╡
│ classifier │ v0.0.2 │
╘════════════╧══════════╛The latest version of classifier is now v0.0.2.
To download the model and use it locally, now we can let GTO resolve the path
from the value stored in artifacts.yaml, and download it using DVC: script and
can use the value stored in the repo:
$ REVISION=[email protected]
$ MODEL_PATH=$(gto describe classifier $REPO --rev $REVISION --path)
$ dvc get $REPO $MODEL_PATH --rev $REVISION -o $MODEL_PATHAssigning stages to deploy a model
Now, we have two registered versions of our model: v0.0.1 and v0.0.2. How do
we get one of them into production? To signal the model version is ready to be
used in some environment, we can assign it to a stage:
$ gto assign classifier \
--repo $REPO \
--version v0.0.2 \
--stage dev
Created Git tag 'classifier#dev#1' that assigns stage
Running `git push origin classifier#dev#1`
Successfully pushed git tag classifier#dev#1 on remote.To actually start the deployment process, we'll need to set up a CI/CD that can be triggered by pushing a Git tag. We'll discuss this in the next section.
Now the model dashboard will be updated with the newly assigned dev stage:
$ gto show --repo $REPO
╒════════════╤══════════╤════════╕
│ name │ latest │ #dev │
╞════════════╪══════════╪════════╡
│ classifier │ v0.0.2 │ v0.0.2 │
╘════════════╧══════════╧════════╛When running gto show for a specific model, we will get all of its registered
versions. Notice that the stage is marked at the latest version that was
assigned to it - to signal the currently deployed model version in that stage:
$ gto show classifier --repo $REPO
╒════════════╤═══════════╤═══════════╤═══════════════════╕
│ artifact │ version │ stage │ ref │
╞════════════╪═══════════╪═══════════╪═══════════════════╡
│ classifier │ v0.0.2 │ dev │ [email protected] │
│ classifier │ v0.0.1 │ │ [email protected] │
╘════════════╧═══════════╧═══════════╧═══════════════════╛Having dozens of models, it’s easier to automate figuring out what versions are
currently assigned to stages. For that, we can use a variation of the show
command. To download the classifier version in dev:
$ REVISION=$(gto show classifier#dev --repo $REPO --ref)
$ MODEL_PATH=$(gto describe classifier --repo $REPO --rev $REVISION)
$ dvc get $REPO $MODEL_PATH --rev $REVISION -o $MODEL_PATHStarting CI/CD for new versions and assignments
CI/CD is a common way to set up some automation - including building your models into Docker images or deploying them to Kubernetes or SageMaker. Since new versions and stage assignments are implemented using Git tags, they can automatically kick off CI/CD process that you can set up with GitHub Actions or any other CI/CD tool, allowing you to programmatically react with actions you would like to perform.
Showing a full CI/CD example is worthy of a dedicated blog post, so we’ll save
it for another time. If you want to see how it works, there are two examples in
the GTO example repo. The
one in the main branch
shows how to parse a Git tag
to react on new versions and stage assignments differently, while the other in
the mlem branch explains
how to deploy your model in a single line
with
MLEM.
Taking a high-level look at our Model Registry
We just learned how to register semantic model versions, assign stages to them, and employ CI/CD to act on those, all using a GitOps approach. Used together with DVC, this allows us to accomplish the main use cases for a powerful model registry, while not introducing any extra services and staying inside a Git Repo.
As we saw above, GTO works within a single repo and requires you to work in CLI. To lift these limitations, we introduced Iterative Studio Model Registry which, in a nutshell, is a friendly UI that allows you to work with GTO artifacts gathered from multiple repositories. This is what Studio Model Registry will look like if you log in and add the repo:
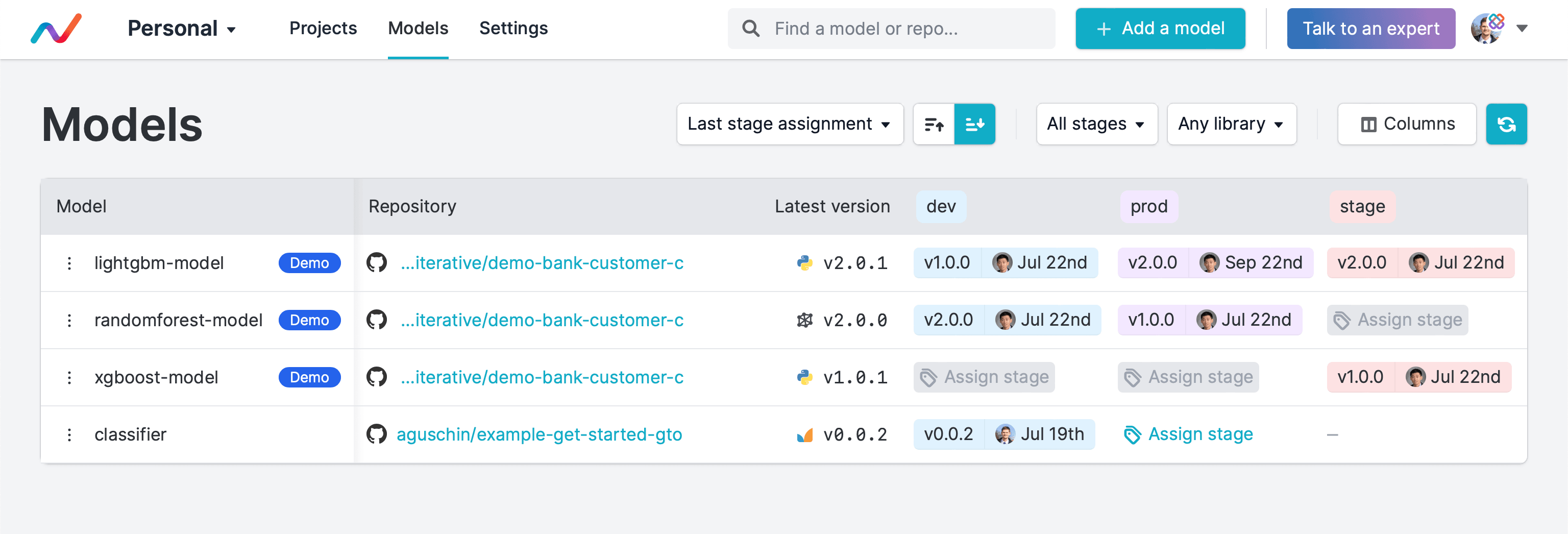
Besides the classifier model that we just registered, you can also see three
other models from our example demo-bank-customer-churn repo.
Behind the scenes, Iterative Studio just uses GTO API, so there are no new magic tricks here (and you can also use GTO API from your automation Python code if you wish). Feel free to play around to register more versions, assign stages or annotate the other models you have, and see how Studio can help you track model lineage, audit events, and connect model versions to DVC experiments.
What’s next?
Check out GTO docs to learn more about the tool and ask us questions in Discord - we’re happy to help you!
Take a look at our public Model Registry so you can see for yourself how Iterative Studio puts together a Git based Model Registry experience.
Share your feedback in Discord or GitHub issues to help us build an open-source Model Registry on top of Git, so you can stick to an existing software engineering stack. No more divide between ML engineering and operations!