Managing OpenFOAM Physical Simulations with DVC, CML, and Studio (Part 2)
Time to celebrate our achievements and let automation take care of the details! We run OpenFOAM simulations in the cloud with our CI/CD tool CML and GitLab using AWS Computational resources. We then can easily visualize and share the simulation results with colleagues in Iterative Studio.







In the previous post, we discussed how DVC simplifies physical simulation pipelines and data management. This post discusses how to run simulations in the cloud, run new experiments, and visualize simulation results with Iterative Studio and other tools.
In this post, you will learn how to:
-
Manage computational resources on AWS and start and shut down EC2 instances for simulation experiments.
-
Run new OpenFOAM simulations in a cloud using Iterative Studio and CML.
-
Use Iterative Studio to view simulation results and DVC plots online.
This post is a result of collaboration between the Iterative.ai and PlasmaSolve teams. PlasmaSolve was founded in 2016 by plasma physicists and software engineers to provide a platform for cutting-edge physics simulation services and research. The PlasmaSolve team strives to deliver top-notch solutions and well-designed physics simulations to speed up research and reduce development costs using various open-source and commercial simulation tools.
Run simulations in the cloud with GitLab and CML
For this part of the post, we follow the main branch in the
demo repository.
Please follow the
README
to prepare your environment and install dependencies.
OpenFOAM simulations can be computationally intensive, requiring access to high-performance computing resources or a cluster of computers to solve large or complex problems.
To run the demo simulation in AWS we may apply CML (Continuous Machine Learning). CML can start a new AWS EC2 instance to run a new simulation experiment and shut it down when it’s done.
The full configuration for the demo CI pipeline can be found in the
.gitlab-ci.yml
file.
The demo project shows an example of how to integrate CML into GitLab CI
configuration. The pipeline has two stages: build and run. The build stage
has a single job that builds a docker image based on the specified Dockerfile,
pushes the image to Amazon Elastic Container Registry (ECR), and logs in to the
registry. The run stage has three jobs: launch, run, and report. The
launch job launches an EC2 instance on Amazon Web Services (AWS) and the run
job runs a simulation on the instance. The report job generates a report on
the simulation results. Visual representations of the CI pipeline and used AWS
services are shown in the diagram below.
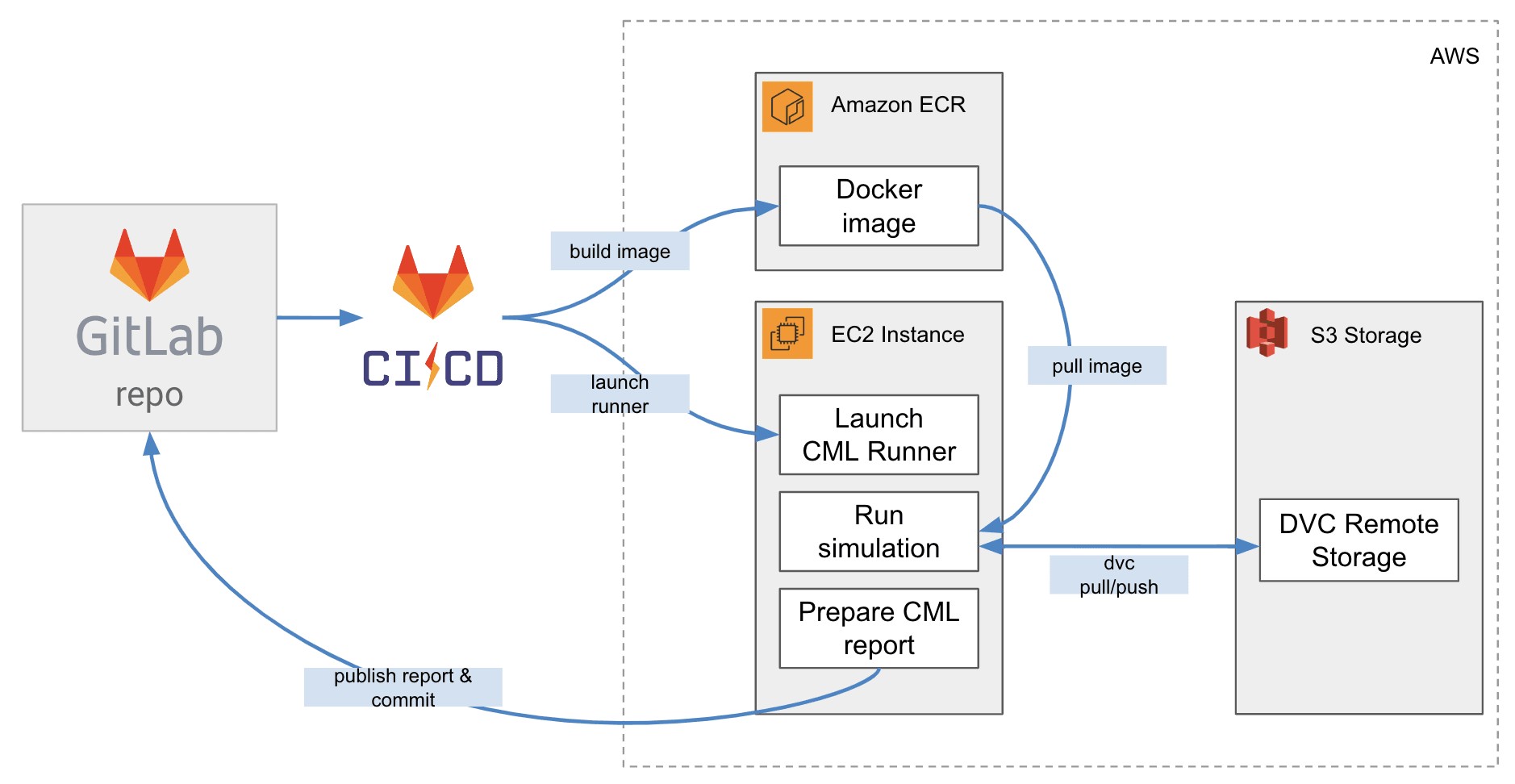
Using AWS computational resources
When a workflow requires computational resources (such as GPUs), CML can automatically allocate cloud instances using cml runner. You can spin up instances on AWS, Azure, GCP, or Kubernetes (see below). Alternatively, you can connect to any other computing provider or an on-premise (local) machine.
Below is an example of the GitLab CI launch job configuration that allocates
AWS instances using cml runner command. Users may define the region, instance
type, and storage size that are needed:
launch:
stage: run
rules:
- changes: [dvc.yaml, params.yaml, .gitlab-ci.yml]
image: iterativeai/cml:0-dvc2-base1
script: >
cml runner launch
--cloud=aws
--cloud-region=$AWS_DEFAULT_REGION --cloud-type=m5.2xlarge
--cloud-hdd-size=32 --labels=cml
--docker-volumes="/home/.cml/cache:/home/.cml/cache"Setup CI jobs to run a simulation
To run a new simulation experiment using the cml runner we need to specify the
cml tag in the run job and run dvc exp run command.
run:
stage: run
tags: [cml]
rules:
- changes: [params.yaml, .gitlab-ci.yml]
image: ${AWS_CONTAINER_IMAGE}
script:
...
# Run an experiment
- dvc pull || echo "Pull failed" # Pull outputs of previous simulation if any
- dvc exp run -f
- dvc push # Save results
- rsync -r ./ /home/.cml/cache/run # Share results with 'report' jobUsing dvc pull command helps to download the results of the previous
experiments from the remote storage. Checking versions of previous results and
DVC pipeline stage dependencies, DVC may skip running stages that do not need to
be run and save a lot of time and computational resources. After the simulation
completes, dvc push uploads the new results back to the remote storage.
After the run job completes, the report job prepares and publishes the CML
report to the associated Git commit. For this, we need to build a report.md
file with all text & plots in Markdown format, and use the cml comment create
command to publish this report and create a pull request.
report:
...
image: iterativeai/cml:0-dvc2-base1 # Python, DVC, & CML pre-installed
script:
...
# Create CML report
- |
cat <<EOF > report.md
...

EOF
- cml comment create --publish-native report.md
- cml pr create .In some cases, these reports may help to collaborate with teammates using a Git workflow.
Setup GitLab CI variables
To run simulations in AWS with GitLab CI & CML, it's recommended to use provider-managed policies/roles and then explicitly limit the permissions further if possible. Here is a set of common permissions required by CML.
In this demo we used the following CI variables in the project
Settings → CI/CD → Variables:
AWS_ACCESS_KEY_IDAWS_SECRET_ACCESS_KEYAWS_SESSION_TOKEN- it is optional and depends on the AWS organization settings.REPO_TOKEN- a personal access token with theapi,read_repositoryandwrite_repositoryscopes. Find more details in CML docs on Personal Access Token
Note: → AWS_SESSION_TOKEN is not required for most users. It’s specific to Iterative's sandbox account. → REPO_TOKEN - a personal access token with the api, read_repository and write_repository scopes. Find more details in CML docs on Personal Access Token.
Experimenting and visualization simulation results in Iterative Studio
Iterative Studio is a web application that you can access online or even host on-prem. Using the power of leading open-source tools DVC, CML, and Git, enables you to seamlessly manage data, run and track experiments, and visualize and share results.
Run a new simulation
Using Iterative Studio we can run new simulation experiments in the Cloud and visualize results in Studio UI.
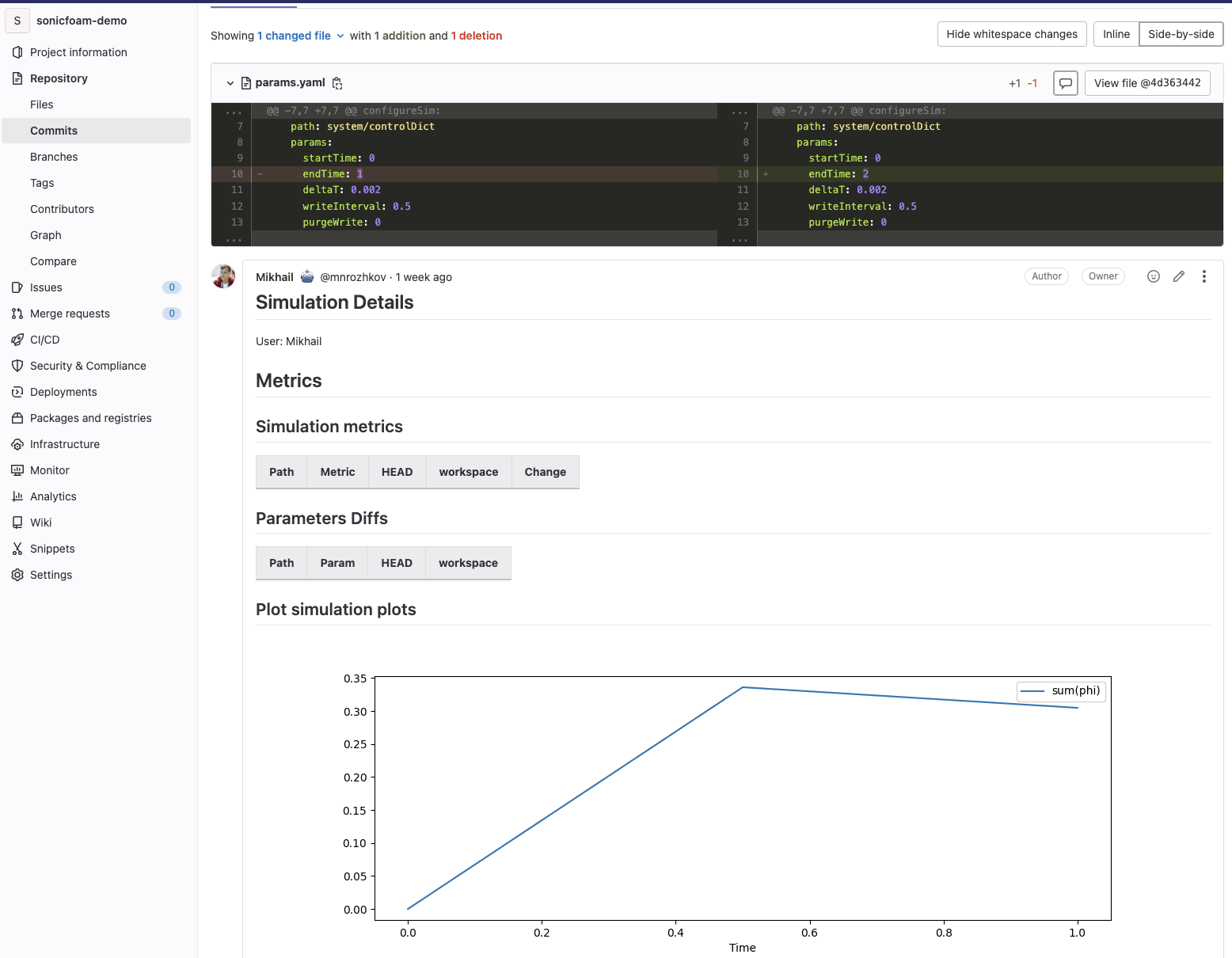
Example of running a new simulation experiment via Iterative Studio
Visualize simulation results
Iterative Studio helps to visualize simulation result images and DVC plots just after the simulation is complete. Studio allows one to plot images and metrics, and compare them with previous simulations.
Example of visualization of simulation results in Iterative Studio
Visualize the simulation outputs with ParaView
OpenFOAM includes several utilities for visualizing simulation results, including ParaView, which is a popular open-source visualization tool. Users can use these tools to generate plots, contour plots, and volume renderings of simulation results.
DVC can help to download the simulation outputs and visualize them locally. One could do a simple command to get all the data generated by the simulation:
$ dvc exp pullDownloaded data can be visualized with third-party tools like ParaView.
Example for sonicFoam simulation results visualized in ParaView
Summary
This post details how Iterative tools help in physical and computational simulations. For this purpose, we created a demo project built with OpenFOAM. The demo shows how to set up DVC for simulation experiments and data management. CML is used in the GitLab CI pipeline to manage computational resources on AWS. Iterative Studio is then used as a UI to visualize simulation results and run new simulations in a few clicks.
Overall, DVC, CML, and Iterative Studio can help OpenFOAM users:
-
Reduce the complexity of simulation pipelines and automate tasks such as running simulations, post-processing results, and generating reports.
-
Manage and track the data and code associated with your OpenFOAM simulations, and make it easier to reproduce simulation results. Store simulation data on-premises or in the cloud using a variety of storage types, such as S3.
-
Manage simulation experiments with simple YAML config files.
-
Manage computational resources on AWS and start and shut down EC2 instances for simulation experiments.
-
Iterative Studio provides a user-friendly interface for simulation results, visualization, and running new simulations quickly.
-
Iterative Studio allows users to view and share simulation results and DVC plots online, without the need to download and visualize results locally.
References
- Why OpenFOAM Users Should Try SimScale
- OpenFoam - Tutorial Guide: Supersonic flow over a forward-facing step
- Introduction to ScalarTransportFoam solver on OpenFoamWiki
scalarTransportFoamTutorial- Walkthrough and tutorial for
scalarTransportFoam: a solver for advection-diffusion of a passive scalar, Eric Paterson and Kevin T. Crofton Department of Aerospace and Ocean Engineering Virginia Polytechnic Institute and State University