May ’19 DVC❤️Heartbeat
Every month we are sharing here our news, findings, interesting reads, community takeaways, and everything along the way. Some of those are related to our brainchild DVC and its journey. The others are a collection of exciting stories and ideas centered around ML best practices and workflow.





Kudos to StickerMule.com for our amazing stickers (and great customer service)!
News and links
This section of DVC Heartbeat is growing with every new Issue and this is already quite a good piece of news!
One of the most exciting things we want to share this month is acceptance of DVC into the Google Season of Docs. It is a new and unique program sponsored by Google that pairs technical writers with open source projects to collaborate and improve the open source project documentation. You can find the outline of DVC vision and project ideas in this dedicated blogpost and check the full list of participating open source organizations. Technically the program is starting in a few months, but there is already a fantastic increase in the amount of commits and contributors, and we absolutely love it!
The other important milestone for us was the first offline meeting with our distributed remote team. Working side by side and having non-Zoom meetings with the team was amazing. Joining our forces to prepare for the upcoming conferences turned out to be the most valuable, educating and uniting experience for the whole team.
It’s a shame that our tech lead was unable to join us it due to another visa denial. We do hope he will finally make it to the USA for the next big conference.

While we were busy finalizing all the PyCon 2019 prep, our own Dmitry Petrov flew to New York to speak at the O’Reilly AI Conference about the Open Source tools for Machine Learning Models and Datasets versioning. Unfortunately the video is available for the registered users only (with a free trial option) but you can have a look at Dmitry’s slides here.
We renamed our Twitter! Our old handle was a bit misleading and we moved from @Iterativeai to @DVCorg (yet keep the old one for future projects).
Our team is so happy every time we discover an article featuring DVC or addressing one of the burning ML issues we are trying to solve. Here are some of our favorite links from the past month:
Version Control For Machine Learning Projects

Version control has become table stakes for any software team, but for machine learning projects there has been no good answer for tracking all of the data that goes into building and training models, and the output of the models themselves. To address that need Dmitry Petrov built the Data Version Control project known as DVC. In this episode he explains how it simplifies communication between data scientists, reduces duplicated effort, and simplifies concerns around reproducing and rebuilding models at different stages of the projects lifecycle.
- Here is an article by Favio Vázquez with a transcript of this podcast episode.
Data version control with DVC. What do the authors have to say?
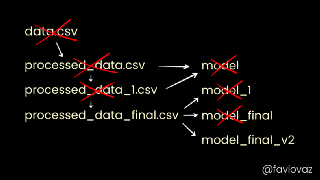
Why Git and Git-LFS is not enough to solve the Machine Learning Reproducibility crisis

With Git-LFS your team has better control over the data, because it is now version controlled. Does that mean the problem is solved? Earlier we said the “key issue is the training data”, but that was a lie. Sort of. Yes keeping the data under version control is a big improvement. But is the lack of version control of the data files the entire problem? No.
Discord gems
There are lots of hidden gems in our Discord community discussions. Sometimes they are scattered all over the channels and hard to track down.
We are sifting through the issues and discussions and share with you the most interesting takeaways.
Q: This might be a favourite gem of ours — our engineers are so fast that someone assumed they were bots.
We feared that too until we met them in person. They appeared to be real (unless bots also love Ramen now)!
Q: Is this the best way to track data with DVC when code and data are separate? Having being burned by this a couple of times, i.e accidentally pushing large files to GitHub, I now keep my code and data separate.
Every time you run dvc add to start tracking some data artifact, its path is
automatically added to the .gitignore file, as a result it is hard to commit
it to git by mistake — you would need to explicitly modify the .gitignore
first. The feature to track some external data is called
external outputs (if
all you need is to track some data artifacts). Usually it is used when you have
some data on S3 or SSH and don’t want to pull it into your working space, but
it’s working even when your data is located on the same machine outside of the
repository.
Q: How do I wrap a step that downloads a file/directory into a DVC stage? I want to ensure that it runs only if file has no been downloaded yet
Use dvc import to track and download the remote data first time and next time
when you do dvc repro if data has changed remotely. If you don’t want to track
remote changes (lock the data after it was downloaded), use dvc run with a
dummy dependency (any text file will do you do not touch) that runs an actual
wget/curl to get the data.
Q: How do I show a pipeline that does not have a default Dvcfile? (e.g. I assigned all files names manually with -f in the dvc run command and I just don’t have Dvcfile anymore)
Almost any command in DVC that deals with pipelines (set of DVC-files) accepts a single stage as a target, for example:
$ dvc pipeline show — ascii model.dvcQ: DVC hangs or I’m getting database is locked issue
It’s a well known problem with NFS, CIFS (Azure) — they do not support file locks properly which is required by the SQLLite engine to operate. The easiest workaround — don’t create a DVC project on network attached partition. In certain cases a fix can be made by changing mounting options, check this discussion for the Azure ML Service.
Q: How do I use DVC if I use a separate drive to store the data and a small/fast SSD to run computations? I don’t have enough space to bring data to my working space.
An excellent question! The short answer is:
# To move your data cache to a big partition
$ dvc cache dir --local /path/to/an/external/partition
# To enable symlinks/harldinks to avoid actual copying
$ dvc config cache.type reflink, hardlink, symlink, copy
# To protect the cache
$ dvc config cache.protected trueThe last one is highly recommended to make links in your working space read-only to avoid corrupting the cache. Read more about different link types here.
To add your data first time to the DVC cache, do a clone of the repository on a
big partition and run dvc add to add your data. Then you can do git pull,
dvc pull on a small partition and DVC will create all the necessary links.
Q: Why I’m getting Paths for outs overlap error when I run dvc add or dvc run?
Usually it means that a parent directory of one of the arguments for dvc add /
dvc run is already tracked. For example, you’ve added the whole datasets
directory already. And now you are trying to add a subdirectory, which is
already tracked as a part of the datasets one. No need to do that. You could
dvc add datasets or dvc repro datasets.dvc to save changes.
Q: I’m getting ascii codec can’t encode character error on DVC commands when I deal with unicode file names
Check the locale settings you have
(locale command in Linux). Python expects a locale that can handle unicode
printing. Usually it’s solved with these commands: export LC_ALL=en_US.UTF-8
and export LANG=en_US.UTF-8. You can place those exports into .bashrc or
other file that defines your environment.
Q: Does DVC use the same logins aws-cli has when using an S3 bucket as its repo/remote storage?
In short — yes, but it can be also configured. DVC is going to use either your
default profile (from ~/.aws/*) or your env vars by default. If you need more
flexibility (e.g. you need to use different credentials for different projects,
etc) check out
this guide
to configure custom aws profiles and then you could use them with DVC using
these
remote options.
Q: How can I output multiple metrics from a single file?
Let’s say I have the following in a file:
{
“AUC_RATIO”:
{
“train”: 0.8922748258797667,
“valid”: 0.8561602726251776,
“xval”: 0.8843431199314923
}
}How can I show both train and valid without xval?
You can use dvc metrics show command --xpath option and provide multiple
attribute names to it:
$ dvc metrics show metrics.json \
--type json \
--xpath AUC_RATIO[train,valid]
metrics.json:
0.89227482588
0.856160272625Q: What is the quickest way to add a new dependency to a DVC-file?
There are a few options to add a new dependency:
-
simply opening a file with your favorite editor and adding a dependency there without md5. DVC will understand that that stage is changed and will re-run and re-calculate md5 checksums during the next DVC repro;
-
use
dvc run --no-execis another option. It will rewrite the existing file for you with new parameters.
Q: Is there a way to add a dependency to a python package, so it runs a stage again if it imported the updated library?
The only recommended way so far would be to somehow make DVC know about your package’s version. One way to do that would be to create a separate stage that would be dynamically printing version of that specific package into a file, that your stage would depend on:
$ dvc run -o mypkgver 'pip show mypkg > mypkgver’
$ dvc run -d mypkgver -d ... -o .. mycmdQ: Is there anyway to forcibly recompute the hashes of dependencies in a pipeline DVC-file?
E.g. I made some whitespace/comment changes in my code and I want to tell DVC “it’s ok, you don’t have to recompute everything”.
Yes, you could dvc commit -f. It will save all current checksum without
re-running your commands.
Q: I have projects that use data that’s stored in S3. I never have data locally to use dvc push, but I would like to have this data version controlled. Is there a way to use the features of DVC in this use case?
Yes! This DVC features is called external outputs and external dependencies. You can use one of them or both to track, process, and version your data on a cloud storage without downloading it locally.
If you have any questions, concerns or ideas, let us know here and our stellar team will get back to you in no time!