




When I was doing my Ph.D., every time I published a paper I shared a public GitHub repository with my dataset and scripts to reproduce my statistical analyses. While it took a bit of work to get the repository in good shape for sharing (cleaning up code, adding documentation), the process was straightforward: upload everything to the repo!
But when I started working on deep learning projects, things got considerably more complicated. For example, in a data journalism project I did with The Pudding, I wanted to understand how hair style (particularly size!) changed over the years. There were a lot of moving parts:
- A public dataset of yearbook photos released and maintained by Ginosar et al.
- A deep learning model I trained to segment the hair in yearbook photos
- A derivative dataset of "hair maps" for each photo in the original datasetr
- All the code to train the deep learning model and analyse the derivative dataset
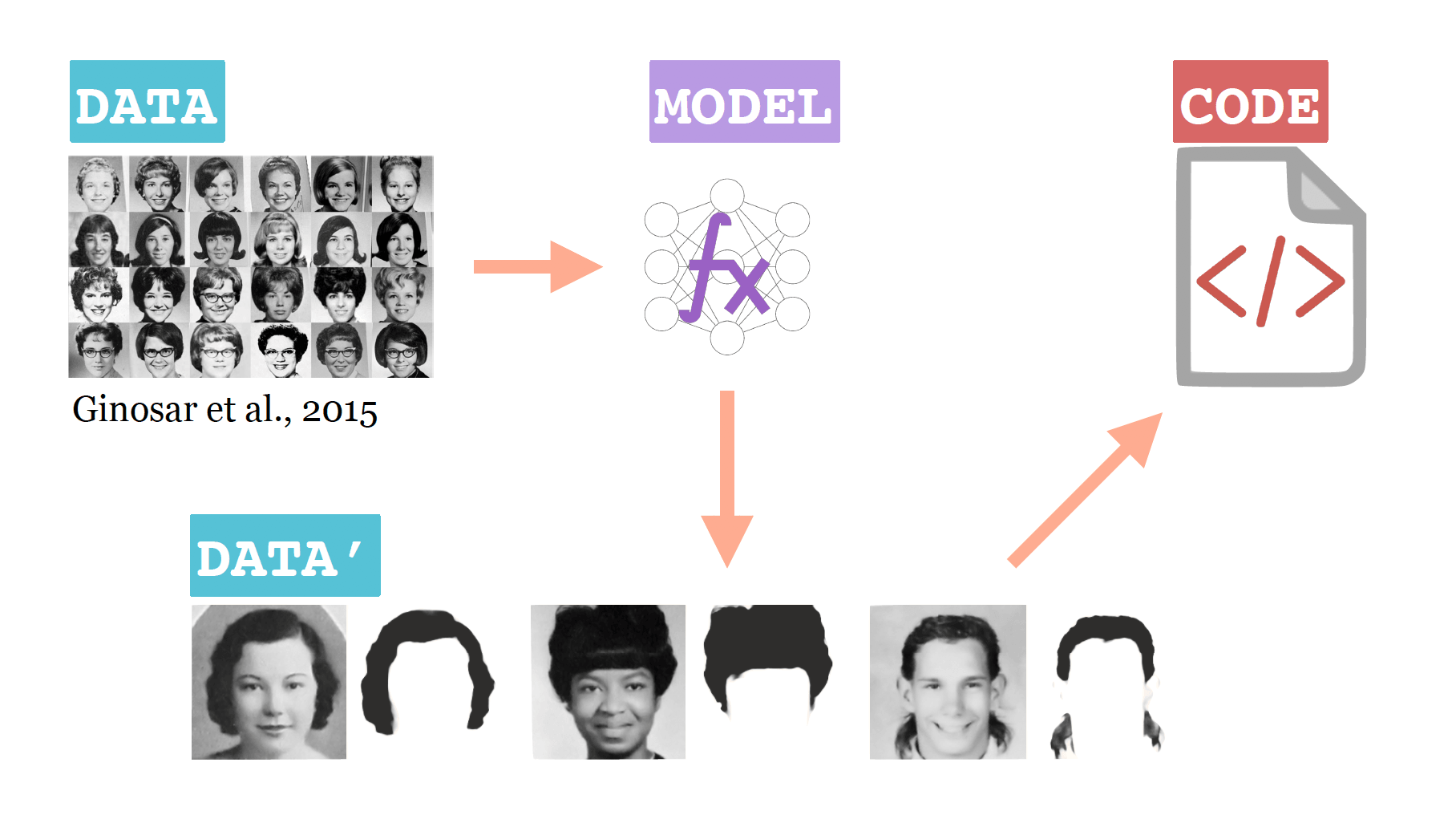
How would you share this with a collaborator, or open it up to the public? Throwing it all in a GitHub repository was not an option. My model wouldn't fit on GitHub because it was over the 100 MB size limit. I also wanted to preserve a clear link between my derived dataset and the original- it should be obvious exactly how I got the public dataset. And if that public dataset were to ever change, I would ideally want it to be clear what version I used for my analyses.
This blog is about several different ways of "releasing" data science projects, with an emphasis on preserving meaningful links about the origins of derived data and models. I'm not making any strong assumptions about whether project materials are relased within an organization (only to teammates, for example) or to the whole internet.
Let's look at a few methods.
Method One: artifacts in the cloud
When you work with big models and datasets, you often can't host them in a
GitHub repo. But you can put them in cloud storage, and then provide a script in
your GitHub repo to download them. For example, in the fantastic gpt-2-simple
project by Max Woolf, Max stores
huge GPT-2 models in Google Drive and provides a script to download a specified
model to a user's local workspace if it isn't already there.
Likewise, the Nvidia StyleGAN release
provides a hardcoded URL to their model in Google Drive storage. Both the
gpt-2-simple and StyleGAN projects have custom scripts to handle these big
downloads, and largely thanks to the work of the project maintainers, users only
interact with the downloading process at a very high level.
Considering some pros and cons of this approach:
| Pros | Cons |
|---|---|
| It's easy to put a model in a bucket | Hardcoded links are brittle |
| Works for pip packages | Need to write custom functions |
| No extra tools, just Python scripting | Downloads aren't versioned |
Method Two: Hubs, Catalogs & Zoos
There are a (growing) number of websites willing to long-term host big models and datasets, plus relevant meta-data, code, and publications. Some even allow you to upload several versions of a project- it's not Git, for sure, but even basic version control is something.
For example, PyTorch Hub lets researchers publish trained models developed in the PyTorch framework, along with code and papers. It's easily searched and browsed, which makes projects discoverable.
For a dataset analog, Kaggle is similar- they host user-submitted datasets and help other users find them. Both PyTorch Hub and Kaggle have APIs for programmatically downloading artifacts.
| Pros | Cons |
|---|---|
| Browsable & discoverable | Centrally managed |
| Public | Public (no granularity) |
| Good with big models | Weak versioning support |
Method Three: Packaging with DVC
DVC, or Data Version Control, is a Python project for extending Git version control to large project artifacts like datasets and models. It's not a replacement for Git- DVC works with Git!
The basic idea is that your datasets and models are stored in a DVC repository, which can be any cloud storage or server of your choice. DVC creates metadata about file versions that can be tracked by Git and hosted on GitHub- so you can share your datasets and models like any GitHub project, with all the benefits of versioning. Let's look at a case study.
Creating a DVC project
Say I have a project containing a dataset, model training code, and model.
$ ls
data.csv
train.py
model.pklSay our model and dataset are large and we want to track them with DVC. For remote storage, we want to use a personal S3 bucket. We would run:
$ git init
$ dvc init
$ dvc remote add myremote s3://mybucket/myproject
$ dvc add data.csv model.pkl
$ dvc pushWhen I run these commands, I've initialized Git and DVC tracking. Next, I've set
a DVC repository- my S3 bucket. Then I've added data.csv and model.pkl to
DVC tracking. Finally, when I run dvc push, the model and dataset are pushed
to the S3 bucket. On my local machine, two meta-files are created:
data.csv.dvc and model.pkl.dvc. These can be tracked with Git!
$ ls
data.csv.dvc
train.py
model.pkl.dvcSo after setting a remote Git repository, git add, commit and push like
usual (assuming you are a regualr Git user, that is):
$ git remote add origin [email protected]:elle/myproject
$ git add . && git commit -m "first commit"
$ git push origin masterPackage management with DVC
Now let's say one of my teammates wants to access my work so far- specifically, they want to see if another method for constructing features from raw data will help model accuracy. I've given them permission to access my GitHub repository. On their local machine, they'll run:
$ dvc import https://github.com/elle/myproject data.csv model.pklThis will download the latest version of the data.csv and model.pkl
artifacts to their local machine, as well as the DVC metafiles data.csv.dvc
and model.pkl.csv indicating the precise version and source.
Collaborators can also download artifacts from previous versions, releases, or
parallel feature branches of a project. For example, if I released a new version
of my project with a Git tag (say v.2.0.1), collaborators can run
$ dvc get --rev v.2.0.1 \
https://github.com/elle/myproject data.csvLastly, because dvc import maintains a link between the downloaded artifacts
and my repository, collaborators can check for project updates with
$ dvc update data.csv model.pklIf new versions are detected, DVC automatically syncs the local workspace with those versions.
When should you do this?
In my own experience releasing a large public dataset with DVC, I've seen several benefits:
- Within an hour, someone found data points I'd been missing. It was straightforward to make a new release after patching this error.
- Several people modeled my dataset! Highly rewarding.
- Since GitHub is a widely used platform for code sharing, it's a natural fit for open source scientific projects and has little overhead for potential collaborators
To return to the pros and cons table:
| Pros | Cons |
|---|---|
| Git version your dataset | No GUI access to files in DVC remote |
| Granular sharing permissions | Collaborators need to use DVC |
| DVC abstracts away download scripts/hardcoded URLs | Can be serverless, but you need to manage cloud storage |
The bottom line
Packaging models and datasets is a non-trivial part of the machine learning workflow. DVC provides a method for giving users a Git-centric experience of cloning or forking these artifacts, with an emphasis on versioning artifacts and abstracting away the processes of uploading, downloading, and storing artifacts. For projects with high complexity- like my hair project, which had some gnarly dependencies and big artifacts- this kind of source control pays off. If you don't know where your data came from or how it's been transformed, it's impossible to be scientific.
Thanks for stopping by our virtual poster! I'm happy to take questions or comments about how version control fits into the scientific workflow. Leave a comment, reach out on Twitter, or send an email.
Further reading
Check out our tutorial about creating a data registry for more code examples.