Serving Machine Learning Models with MLEM
Getting a machine learning model out to our end users can be an involved task. You have to make sure it's in the correct format for the environment and for the way it will be consumed. We're going to walk through how you can use MLEM to save your model and serve it with a web API.





Serving Machine Models with MLEM
Training a machine learning model is only one step in the process of getting something useful out to end-users. When it's time to deploy the model to production, there are a number of approaches you can take depending on the goal of the machine learning project. That might mean getting the model ready to respond to real-time queries coming from an API or batch processing predictions, for example.
Either way, you'll need to save your trained and validated model in a format that's consumable by other systems. That's why we'll be covering how to serve models through a REST endpoint or a Python package with MLEM.
You can get the repo we're working with here.
Take a candidate model
There are instructions in the project README on how to get everything you need installed and running. This is a simple ML project that uses DVC for data versioning and experiment tracking.
After you have the repo set up, you'll already have the mlem package
installed. This project already has a model that's been trained and validated so
we can move on to saving this model.
Save the model
Inside the train.py script, we need to add the mlem import to save the
models as we experiment. We don't have to worry about running the training
script for this project since we have the model, but it's good to know what's
happening under the hood.
# train.py
import os
import pickle5 as pickle
import sys
import yaml
from mlem.api import save
import numpy as np
from sklearn.ensemble import RandomForestClassifier
...Then you can add the save function to the end of the training script.
# train.py
...
clf = RandomForestClassifier(
n_estimators=n_est, min_samples_split=min_split, n_jobs=2, random_state=seed
)
clf.fit(x, labels)
save(
clf,
"clf",
sample_data=x,
description="Random Forest Classifier",
)You don't have to do these steps as we already have a model available, but if you want to see the training and evaluation steps in action, you reproduce the DVC pipeline with:
$ dvc reproYou can check out what is happening in that pipeline by looking at the
dvc.yaml file in the project.
You can also see where we load the model into the src/evaluate.py script. To
do that, you'll need to add the following import.
# evaluate.py
...
import pickle5 as pickle
import sklearn.metrics as metrics
from mlem.api import apply
...Now we can use the apply function
to make predictions with the model.
# evaluate.py
...
x = matrix.iloc[:,1:11].values
cleaned_x = np.where(np.isnan(x), 0, x)
labels_pred = apply(model_file, cleaned_x, method="predict")
predictions_by_class = apply(model_file, cleaned_x, method="predict_proba")
predictions = predictions_by_class[:, 1]
...The predict and predict_proba are methods available from the model and they
are used to get new predicted values and their probabilities for evaluation.
This, along with everything else in the script, is how we get the metrics for
each experiment.
After you run an experiment, there will be two new files in your repo: clf and
clf.mlem. Make sure you add the clf.mlem file to your Git history with the
following command:
$ git add clf.mlemThis is so that the metadata is in your repo and ready to use with other MLEM commands. Now we can finally take the model file and ship it to production!
Deploy the model to production
There are a couple of ways you can do this with MLEM:
- Serve the model with FastAPI.
- Create a Python package (and use or distribute it).
Note: There is an experimental option to deploy the model directly to Heroku although this functionality is experimental and may have breaking changes.
Serve with FastAPI
If you don't have an API to work with and don't need a Python package, like if you're just testing a model, you can serve your model quickly using FastAPI with this command.
$ mlem serve clf fastapiThis will run a local server and spin up a web API for you so you can quickly test out your model without needing a development team to work on the API initially.
You'll see an output like this in your terminal:
$ mlem serve clf fastapi
⏳️ Loading model from clf.mlem
Starting fastapi server...
💅 Adding route for /predict
💅 Adding route for /predict_proba
💅 Adding route for /sklearn_predict
💅 Adding route for /sklearn_predict_proba
Checkout openapi docs at <http://0.0.0.0:8080/docs>
INFO: Started server process [31916]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)Then, when you go to the local URL, you'll see the documentation for how to use the model you created.
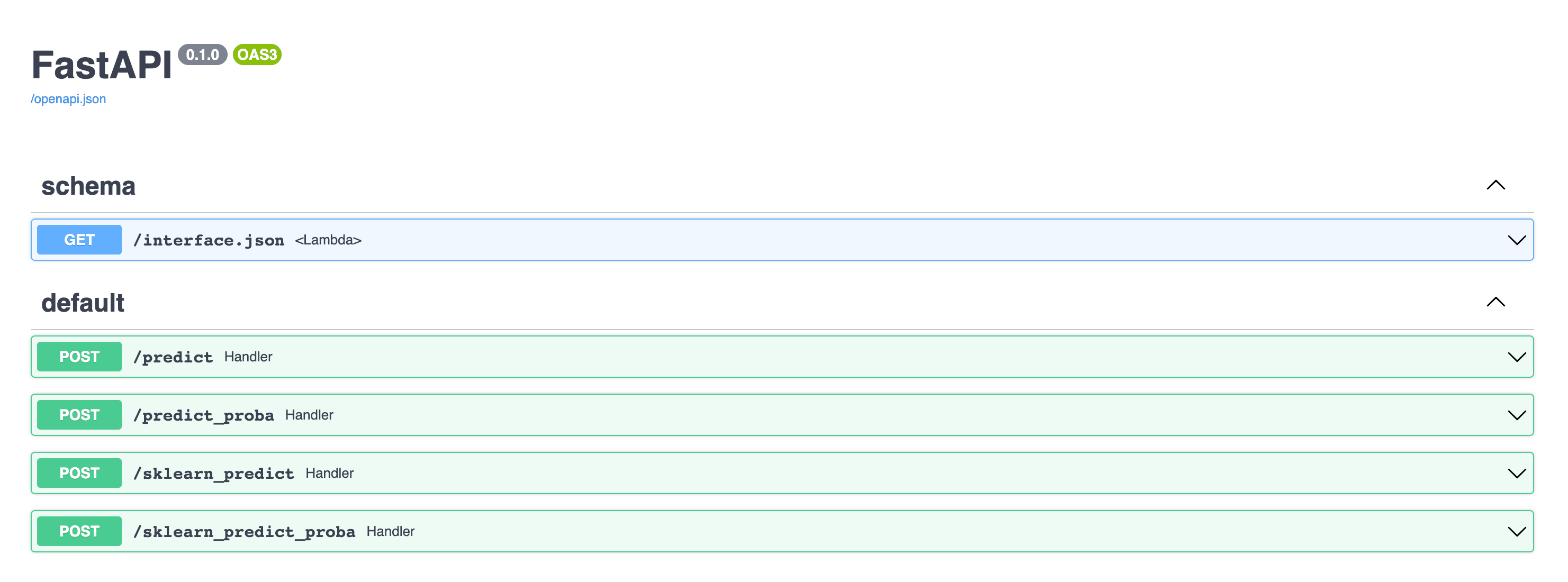
That's it! Now you know how to train a model, save it, and deploy to some external service quickly using MLEM!
Custom Python package
Let's take a look at making a Python package and importing it into a Flask web app. To make the Python package, we'll run the following MLEM command.
$ mlem build clf pip -c target=build/ -c package_name=bike_predictorThis takes our clf.mlem file and generates a Python package called
bike_predictor in the build directory. When you look in your project, you
should see that new build folder that has all of the files you need for an
independent Python package.
To build the package, you'll need to run the following command in the build
directory.
$ python -m build --wheelThen go back to the top-level directory and run the following command to install your new model package.
$ pip install ./build/dist/bike_predictor-0.0.0-py3-none-any.whlnNow you can import this to your Flask API like so.
# api.py
import os
from flask import Flask, jsonify, request
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
from flask_cors import CORS
from dotenv import load_dotenv
import bike_predictor
...You can then use the predict method on new data and run any other tasks you
need to in the API.
# api.py
...
new_event = EventsModel(
title=data["title"],
date=data["date"],
time=data["time"],
location=data["location"],
description=data["description"],
)
db.session.add(new_event)
db.session.commit()
bike_predictor.predict(new_event)
...Then you can test this API out locally by running the following command:
$ python src/api.pyThis will start up a local server on port 5000 and you'll be able to see your model in action. From here, this can be deployed to any cloud environment as long as you remember to include and install the model package.
Conclusion
In this post, we learned how easy it can be to deploy a model through FastAPI or through a Python package with MLEM. You can use this same process to train and serve any model through an API endpoint very quickly. This can help with validation, collaborating with team members, and it can help you see if there are any underlying issues in your overall deployment process before you hear about them from users. MLEM can also be used to create a model registry so you can store and switch between models whenever you need to.